
Golang
前言
Go语言的特点
Go语言保证了既能达到静态编译语言的安全和性能,又达到了动态语言开发维护的高效率
- 从C语言中继承的很多理念,包括表达式语法,控制结构,基础数据类型,调用参数传值,指针等,也保留了和C语言一样的编译执行方式及弱化的指针
- 引入了包的概念,用于组织程序结构,Go语言的一个文件都要归于一个包,而不是单独存在
package main //一个Go文件需要在一个包里 |
垃圾回收机制,内存自动回收,不需要开发人员管理
天然并发:
- 从语言层面支持并发,实现简单
- Goroutine,轻量级线程,可实现大并发处理,高效利用多核
- 基于CPS并发模型(Communicating Sequential Processes)实现
吸收了管道通信机制,形成Go语言特有的管道channel
通过管道channel,可以实现不同的Goroute之间的互相通讯
函数返回多个值
//写一个函数,实现同时返回 和,差 |
- 新的创新:切片,延迟执行defer等
Go语言的快速开发入门
Go语言的开发步骤
目录结构
GoProject/src/Go_Code/Project01/main/hello.go
//要求开发一个hellow.go,可以输出“hello, world!” |
Go文件的后缀是.go
package main表示hello.go文件所在包是main,在go中,每个文件必须归属于一个包
import “fmt”表示:引入一个包,包名fmt,引入该包后,就可以使用fmt包的函数
func main(){
} func是一个关键字,表示一个函数,main是函数名
fmt.Println(“hello,world!”)表示调用fmt包里的函数,输出hello,world!
通过 go build 命令(在dos中执行)对该go文件进行编译,生成.exe文件
运行.exe文件即可
Go的执行流程
.go文件 —-(编译)—->可执行文件(.exe)—-(运行)—->结果
- 如果我们先编译生成可执行文件,那么我们可以将该可执行文件拷贝到没有go开发环境的机器上,仍然可以运行
- 如果我们是直接go run go源代码,那么如果在另一台机器上这么运行,也需要go开发环境,否则无法执行
- 在编译时,编译器将程序运行依赖的库文件包含在可执行文件中,所以可执行文件会变大很多
Go开发注意事项
- Go原文家以“go”为扩展名
- Go应用程序的执行入口时main()方法
- Go语言严格区分大小写
- Go方法由一条条语句构成,每条语句后面不带分号
- Go编译器时一行行进行编译的,不可将多条语句写入同一行
- Go语言定义的变量或者import的包如果没有使用到,代码编译不能通过
- 大括号成对出现缺一不可
Go语言的转义字符
// \t :一个制表位,实现对齐功能 |
// \n :换行符 |
// \\ :一个\ |
// \" :一个" |
// \r :回车 |
Go语言注释(comment)
介绍:用于注释说明解释程序的文字就是注释,注释是为了提高代码的阅读性;注释是一个程序员必须要有的良好编程习惯。将自己的思想通过注释先整理出来,再用代码去提现
注释类型
- 行注释
// 注释内容 |
- 块注释
/*注释内容(一次可注释多行,不可嵌套)*/ |
规范的代码风格
正确的注释和注释风格:推荐使用行注释来注释整个方法和语句
正确的缩进和空白:shift+tab整体向左移动,tab整体向右移动
运算符两边各加一个空格
Golang标准库API文档
- API(Application Programming Interface 应用程序编程接口)是Golang提供的基本的编程接口
- Go语言提供了大量的标准库,因此google公司也为标准库提供了相应的API文档,用于告诉开发猪如何使用这些标准库,以及标准库包含的方法
- Golang中文网在线标准库文档:Golang标准库文档
变量
变量相当于内存中的一个数据存储空间的表示
变量的使用步骤:
- 变量的声明(定义变量)
- 变量赋值
- 变量使用
package main |
注意事项和使用细节:
- 变量表示内存中的一个存储区域
- 该区有自己的名称(变量名)和类型(数据类型)
- Golang变量使用的三种方式
- 指定变量类型,声明后若不赋值,使用默认值
- 根据值自行判断变量类型(类型推导)
- 省略var,注意 := 左侧的变量不应该是已经申明过的,否则导致编译错误
package main |
- 多变量声明:在编程中,我们需要一次性声明多个变量
package main |
//一次声明多个全局变量 |
- 该区域的数值可以在同一类型范围内不断变化
- 变量在同一作用域内不能重名
- 变量 = 变量名 + 值 + 数据类型
- Golang的变量如果没有赋初值,编译器会使用默认值
程序中 + 的使用
package main |
常量
- 常量使用const修改
- 常量在定义的时候,必须初始化
- 常量不能修改
- 常量只能修饰bool、数值类型(int、float类型)、string类型
- 语法:const indentifier [type] = value
注意事项和使用细节:
- 比较简单的写法
const( |
- 还有一种专业的写法
const( |
- Golang中没有常量名必须字母大写的规范,比如TAX_RATE
- 仍然通过首字母的大小写来控制常量的访问范围
数据类型
整数类型
整数类型分类:
- int8:有符号,占存储空间1字节,表示范围-128~127
- int16:有符号,占存储空间2字节,表示范围-2^15^~2^15^-1
- int32:有符号,占存储空间4字节,表示范围-2^31^~2^31^-1
- int64:有符号,占存储空间8字节,表示范围-2^63^~2^63^-1
- uint8:无符号,占存储空间1字节,表示范围0~255
package main |
- byte:无符号,占存储空间1字节,表示范围0~255,处理字符
- rune:有符号,占存储空间4字节,表示范围-2^31^~2^31^-1,处理中文
注意事项和使用细节:
- Golang各整数类型分:有符号和无符号,int unit的大小和系统有关
- Golang的整型默认声明为int型
- 如何在程序查看某变量的字节大小和数据类型
- Golang程序中整型变量在使用时,遵守保小不保大的原则,即:在保证程序正确运行下,尽量使用占用空间小的数据类型
- bit:计算机中最小的存储单位。byte:计算机中基本的存储单元
//如何查看一个变量的格式 |
小数类型/浮点类型
基本介绍:小数类型就是用于存放小数的
package main |
小数类型分类:
- 单精度float32:占用空间4字节,表示范围-3.403E38~3.403E38
- 双精度float64:占用空间8字节,表示范围-1.798E308~1.798E308
说明:
- 关于浮点数在机器中存在的形式简单说明,浮点数=符号位+指数位+尾数位(说明所有浮点数都是有符号位的)
- 尾数部分可能会丢失,造成精度损失
package main |
注意事项和使用细节:
- Golang浮点类型有固定的范围和字节长度,不受具体OS的影响(注意:Golang中没有float,只有float32和float64)
- Golang的浮点型默认声明为float64
- 浮点型常量有两种表示形式
- 十进制数形式,如:5.12
- 科学计数法形式,如:5.1234e2 = 5.12*10^2^
- 通常情况下,应该用float64,因为它比float32更健康
字符类型
基本介绍:Golang没有专门的字符类型,如果需要存储单个字符(字母),一般使用byte来保存
字符串就是一串固定长度的字符连接起来的字符序列。Go的字符串是有单个字节连接起来的。也就是说对于传统的字符串是有字符组成的,而Go的字符串不同,它是由字节组成的
package main |
注意事项和使用细节:
- 字符常量是用单引号(‘ ‘)括起来的单个字符
- Go中允许使用转义字符’'将其后的转义字符变为特殊字符常量
- Go语言的字符使用UTF-8编码
- 在Go中,字符的本质是一个整数,直接输出时,是该字符对应的UTF-8编码的码值
- 可以直接给某个变量附一个数字,然后按格式化输出时%c,会输出改数字对应的unicode字符
- 字符类型是可以进行运算的,相当于一个整数,因为他都对应有Unicode码
package main |
字符类型的本质探讨
- 字符型存储到计算机中,需要将字符对应的码值(整数)找出来
- 存储:字符->对应码值->二进制->存储
- 读取:二进制->码值->字符->读取
- 字符和码值的对应关系是通过字符编码表决定的(规定好的)
- Go语言的编码统一成了UTF-8。方便切统一,没有乱码困扰
布尔类型
基本介绍:
- 布尔类型也叫bool类型,bool类型只允许取值true和false
- bool类型占1个字节
- boolean类型适于逻辑运算,一般用于程序流程控制
package main |
字符串类型
基本介绍:字符串就是一串固定长度的字符连接起来的字符序列,Go的字符串是有单个字节连接起来的。Go语言的字符串的的字节使用UTF-8编码表示UniCode文本
package main |
注意事项和使用细节:
Go语言的字符串的字节使用UTF-8编码表示UniCode文本,这样Golang统一使用UTF-8编码吗,中文乱码问题不会困扰程序员
字符串一旦赋了值,字符串就不能修改了:在Go中字符串是不可变的
字符串的两种表示形式
- 双引号(“ “),会识别转义字符
- 反引号(``),以字符串的原生形式输出,包括换行和特殊字符,可以实现防止攻击、输出源代码等效果
字符串拼接方式
var str string |
- 当一行字符串太长时,需要使用多行字符串
str := "hello " + //加号需要在上一行 |
Golang的基本数据类型的默认值
基本介绍:在Go中,数据类型都有一个默认值,当程序员没有赋值时,就会保留默认值。在Go中,默认值叫零值
基本数据类型的默认值如下:
package main |
基本数据类型转换
基本介绍:Golang和java/c不同,Go在不同类型的变量之间赋值需要显示转换(强制转化)。也就是说Golang中数据类型不能自动转换
基本语法:
表达式T(v)将值v转化为T
- T:就是数据类型,例如int32,int64,float32等
- v:就是需要转换的变量
var i int32 = 100 |
注意事项和使用细节:
- Go中,数据类型的转换可以是从表示范围小->表示范围大,也可以 范围大->范围小
- 被转化的是变量存储的数据(即值),变量本身的数据类型没有变换
- 再转换中,将int64转换为int8,编译时不会报错,只是转换结果是按照溢出处理
基本数据类型转换为string
基本介绍:在程序开发中,我们经常需要将基本数据类型转成string类型,或者将string转换为基本数据类型
- 方式一: fmt.Sprintf(“%参数”, 表达式)
Sprintf根据format参数生成格式化的字符串并返回该字符串
package main |
- 方式二:使用strconv包中的函数
package main |
string转换为基本数据类型
- 方式:使用strconv包的函数
package main |
注意事项和使用细节:
在将string类型转成基本数据类型时,要确保string类型能够转成有效的数据。如果转换失败,则接收值类型为目标类型,但接收值的值为默认值
指针类型
基本介绍:
- 基本数据类型,变量存的就是值,也叫值类型
- 获取变量的地址,用&。比如:var num in,获取num的地址:&num
- 指针类型,变量存的是一个地址,这个地址指向的空间存的才是值。比如:var ptr *int = &num
- 获取指针类型所指向的值,用*。比如var *ptr int,使用 *ptr获取p指向的值
package main |
//通过ptr指针修改num的值 |
注意事项和使用细节
- 值类型,都有对应的指针类型,形式为*数据类型,比如int的对应指针就是 *int,float32对应的指针就是 *float32,以此类推
- 值类型包括:基本数据类型int系列,float系列,bool,string、数组和结构体struct
值类型和引用类型
- 常见的值类型:基本数据类型int系列,float系列,bool,string、数组和结构体struct
- 常见的引用类型:指针、slice切片、map、管道chan、接口interface等
值类型和引用类型的区别:
- 值类型:变量直接存储值,内存通常在栈中分配
- 引用类型:变量存储的是一个地址,这个地址对应的空间才是真正存储数据(值),内存通常在堆上分配,当没有任何变量引用这个地址时,该地址对应的数据空间就成为一个垃圾,由GC回收
标识符的命名规范
基本介绍:
- Golang对各种变量、方法、函数等命名时使用的字符序列成为标识符
- 凡是自己可以起名字的地方都叫标识符
标识符的命名规则:
- 由26个英文字母大小写,0-9,_ 组成
- 数字不可以开头
- Golang中严格区分大小写
- 标识符不能包含空格
- 下划线”_”本身在Go中是一个特殊的标识符,称为空标识符。可以代表任何其他的标识符,但是它对应的值会被忽略(比如:忽略某个返回值)。所以仅能被作为占位符使用,不能作为标识符使用
- 不能一系统保留关键字作为标识符,比如break,if等
注意事项和使用细节:
- 包名:保持package的名字和目录保持一致,尽量采取有意义的包名,简短,有意义,不要和标准库冲突
- 变量名、函数名、常量名:采用驼峰法
- 如果变量名、函数名、常量名首字母大写,则可以被其他的包访问;如果首字母小写,则只能在本包中使用(注:可以简单的理解成,首字母大写是公有的,首字母小写是私有的),在Golang中没有public、private等关键字
保留关键字和预定义标识符
包里关键字介绍:
在Go中,为了简化代码的编译过程中对代码的解析,其定义的保留关键字只有25个,如下:
break、default、func、interface、select、case、defer、go、map、struct、chan、else、goto、package、switch、const、fallthrough、if、range、type、continue、for、import、return、var
预定义标识符介绍:
除了保留关键字外,Go中还提供了36个预定义标识符,其中包括基础数据类型和系统内嵌函数
append、bool、byte、cap、close、complex、complex64、complex128、uint16、copy、false、float32、float64、imag、int、int8、int16、int32、int64、ioat、len、make、new、nil、panic、uint64、print、println、real、recover、string、true、uint、unit8、uintprt
运算符介绍
运算符是一种特殊的符号,用以表示数据的运算、赋值和比较等
算数运算符
基本介绍:算术运算法是对数值类型的变量进行运算的,比如:加减乘除等
package main |
注意事项和使用细节:
- 对于除号” / “,它的整数除和小数除是有区别的,整数之间做除法时,只保留整数部分而舍弃小数部分
- 当对一个数取模时,可以等价a % b = a - b / b * b
- Golang的自增自减只能当做一个独立语言使用
- Golang的++和–只能写在变量后面,不能写在变量前面
- Golang的设计者去掉c / java中的自增自减的容易混淆的写法,让Golang更加简洁,统一
关系运算符
基本介绍:
- 关系运算符的结果都是bool型,也就是要么是true,要么是false
- 关系表达式经常用在if结构的条件中或循环结构的条件中
package main |
注意事项和使用细节:
- 关系运算符的结果都是bool型,也就是要么是true,要么是false
- 关系运算符组成的表达式,我们称为关系表达式
- 关系运算符” == “不能误写成” = “
逻辑运算符
基本介绍:用于连接多个条件(一般来讲就是关系表达式),最终结果也是一个bool值
package main |
注意事项和使用细节:
- &&也叫短路与,如果第一个条件为false,则第二个条件不会判断,最终结果为false
- ||也叫短路或,如果第一个条件为true,则第二个条件不会判断,做种结果为true
赋值运算符
基本介绍:赋值运算符就是将某个运算后的值,赋给指定的变量
package main |
注意事项和使用细节:
- 运算顺序从右向左
- 赋值运算符的最左边只能是变量,右边可以是变量、表达式、常量值
- 复合赋值运算符等价效果
其他运算符
- &:返回变量存储地址,&a将给出变量的实际地址
- *:指针变量, *a是一个指针变量
特别说明:Go语言中不支持三目运算符,可以使用if-else来实现
运算符的优先级
- 运算符有不同的优先级,所谓优先级就是表达式运算中的运算顺序
- 只有单目运算符、赋值运算符是从右向左
- 大致顺序:括号 ++ –、单目运算、算数运算、移位运算、关系运算、位运算、逻辑运算、赋值运算、逗号
- 后缀:() [] {} -> . ++ – 左到右
- 单目:+ - ! ~ (type) * & sizeof 右到左
- 乘法:* / % 左到右
- 加法:+ - 左到右
- 移位:>> << 左到右
- 相等: == != 左到右
- 按位AND:& 左到右
- 按位XOR:^ 左到右
- 按位AND:| 左到右
- 逻辑AND:&& 左到右
- 逻辑OR:|| 左到右
- 赋值运算符:= += -= *= /= %= >>= <<= &= ^= |= 右到左
- 逗号:, 左到右
获取用户中端输入
键盘输入语句
基本介绍:在编程中,需要接收用户输入的数据,就可以使用键盘输入语句来获取
步骤:
- 导入fmt包
- 调用fmt包中函数fmt.Scanln()或fmt.Scanf()
package main |
package main |
进制
进制介绍
对于整数,有四种表示方式
- 二进制:0,1,满二进一
- 十进制:0-9,满十进一
- 八进制:0-7,满八进一,以数字0开头表示
- 十六进制:0-9及A-F,满十六进一,以0x或0X开头表示
进制的转换
其他进制转十进制
二进制转十进制
规则:从最低位开始(右边),将每个位上的数提取出来,乘以2的(位数-1)次方,然后求和
案例:1011 = 1 * 1 + 1 * 2 + 0 * 2 * 2 + 1 * 2 * 2 * 2 = 1 + 2 + 0 + 8 = 11
八进制转十进制
规则:从最低位开始(右边),将每个位上的数提取出来,乘以8的(位数-1)次方,然后求和
案例:0123 = 3 * 1 + 2 * 8 + 1 * 8 * 8 = 3 + 16 + 64 = 83
十六进制转十进制
规则:从最低位开始(右边),将每个位上的数提取出来,乘以16的(位数-1)次方,然后求和
案例:0x34A = 10 * 1 + 4 * 16 + 3 * 16 * 16 = 10 + 64 + 768 = 842
十进制转其他进制
十进制转二进制:将该数不断除以2,直到商为0为止,然后将每步得到的余数倒过来,就是对应的二进制
案例:56(十进制) = 111000(二进制)
十进制转八进制:将该数不断除以8,直到商为0为止,然后将每步得到的余数倒过来,就是对应的二进制
案例:156(十进制) = 0234(八进制)
十进制转十六进制:将该数不断除以16,直到商为0为止,然后将每步得到的余数倒过来,就是对应的二进制
案例:356(十进制) = 0x164(十六进制)
二进制转其他进制
二进制转八进制:将二进制数每三位一组(从低位开始组合),转成对应的八进制数即可
案例:11 010 101(二进制) = 0325(八进制)
二进制转十六进制:将二进制数每四位一组(从低位开始组合),转成对应的十六进制数即可
案例:1101 0101(二进制) = 0xD5(十六进制)
其他进制转二进制
八进制转二进制:将八进制每一位,转成对应的三位二进制数即可
案例:0237(八进制) = 10 011 111(十六进制)
十六进制转二进制:将十六进制每一位,转成对应的四位二进制数即可
案例:0x237(十六进制) = 10 0011 0111(二进制)
反码 原码 补码
二进制在运算中的说明
二进制是逢二进位的进位制,0、1是基本算符。
现代的电子计算机技术全部采用的是二进制,因为它使用0、1两个数字符号,非常简单方便,易于用电子方式实现。计算机内部处理的信息,都是采用二进制数来表示的。二进制(Binary)数用0和1两个数字及其组合来表示任何数。进位规则是“逢二进一”,数字1在不同位上代表不同值,按从右至左的次序,这个值以二倍递增
原码、反码、补码
对有符号数而言:
- 二进制最高位是符号位:0表示正数,1表示负数
- 正数的原码、反码、补码都是一样的
- 负数的反码等于它的原码符号位不变,其他位取反
- 负数的补码等于它的反码加一
- 1 ->原码[0000 0001]、反码[0000 0001]、补码[0000 0001]
- -1 ->原码[1000 0001]、反码[1111 1110]、补码[1111 1111]
- 0的反码、补码都是0
- 在计算机运行时候,都是以补码的方式来运算
位运算
Golang中有三个位运算:分别是按位与&、按位或|、按位异或^
- 按位与&:两位全为1,结果为1,否则为0
- 按位或|:两位有一个为1,结果为1,否则为0
- 按位异或^:两位相同为0,不同为1
案例:
- 2&3:0000 0010 & 0000 0011 = 0000 0010 = 2
- 2|3:0000 0010 | 0000 0011 = 0000 0011 = 3
- 2^3:0000 0010 ^ 0000 0011 = 0000 0001 = 1
- -2^2:1111 1110 ^ 0000 0010 = 1111 1100 = -4
Golang中有两个移位运算符:
- 右移运算符>>:低位溢出,符号位不变,并用符号位补溢出的高位
- 左移运算符<<:符号位不变,低位补0
案例:
- 1>>2:0000 0001 >> 0000 0000 = 0
- 1<<2:0000 0001 << 0000 0100 = 4
程序流程控制
在程序中,程序运行的流程控制决定程序是如何执行的,使我们必须掌握的,主要有三大流程控制语句:
- 顺序控制
- 分支控制
- 循环控制
顺序控制介绍
程序从上到下逐行地执行,中间没有任何判断和跳转
//在下列代码中,没有判断和跳转 |
注意事项和使用细节:
先声明在使用,不可先试用在声明;必须自上而下
分支控制介绍
分支控制if-else介绍
让程序有选择执行,分支控制有三种:单分支;双分支;多分支
单分支
//单分支基本语法 |
说明:
当条件表达式为true是,就会执行{ }的代码
{ }是必须有的,就算只有一行代码
Golang支持在if语句中直接定义一个变量
if age := 20; age > 18 { //支持在if语句中直接定义一个变量 |
双分支
//双分支基本语法 |
说明:
- 当条件表达式成立,即执行代码块1,否则执行代码块2
- { }必须存在
- else必须紧接着if{ }后面写,不可换行
if age > 18 { //支持在if语句中直接定义一个变量 |
多分支
//多分支基本语法 |
说明:
- 多分支的判断流程如下
- 先判断条件表达式1是否成立,如果为真,执行代码块1
- 如果条件表达式1不成立,判断条件表达式2是否成立,以此类推
- 如果所有条件表达式都不成立,则执行else中的代码块
- else不是必须的
- 多分支最多只有一个入口
if score == 100 { |
注意事项和使用细节:
若一个分支条件表达式与其后分支条件表达式有重叠部分,则先到先得
var i int = 10 |
嵌套分支
一个分支结构中又完整的嵌套了另一个完整的分支结构,里面的分支的结构称为内层分支外面的分支结构称为外层分支
//嵌套分支基本语法 |
说明:嵌套分支不宜过多,最多我们建议控制在三层
switch分支结构
- switch语句用于基于不同条件执行不同动作,每一个case分支都是唯一的,从上到下逐一测试 ,直到匹配为止
- 匹配项后面也不需要再加break
switch 表达式 { |
switch执行流程:
- switch的执行的流程是,先执行表达式,得到值,然后和case的表达式进行比较,如果相等,就匹配到,然后执行对应的case的语句块,然后退出switch
- 如果switch的表达式的值没有和任何的case的表达式匹配成功,则执行default的语句块。执行后退出switch的控制
switch使用细节:
- case后面是一个表达式(即:常量值、变量、一个有返回值的函数等都可以)
- case后的各个表达式的值得数据类型,必须和switch的表达式数据类型一致
- case后面可以带多个表达式,使用逗号间隔。比如case 表达式1, 表达式2…
- case后面的表达式如果是常量值(字面量),则要求不能重复
- case后面不需要带break
- default语句不是必须的
- switch后也可以不带表达式,类似多个if-else分支来使用
- switch后也可以直接声明一个变量,分号结束,不推荐
- switch穿透-fallthrough,如果case语句块后增加fallthrough,则会执行下一个case,也叫switch穿透(默认只能穿透一层)
- Type switch:switch语句还可以被用于type-switch来判断某个interface变量中实际指向的变量类型
switch与if比较
- 如果判断的具体数值不多,而且符合整数、浮点数、字符、字符串这几种类型。建议使用switch语句,简洁高效
- 其他情况,对区间判断的结果为bool类型的判断,使用if,if的使用范围更广
循环控制介绍
循环介绍
让代码块可以循环执行
package main |
for循环控制
//for循环基本语法 |
for循环四要素:
- 循环变量初始化
- 循环条件
- 循环操作(循环体)
- 循坏变量的迭代
注意事项和使用细节:
- 循环条件是返回一个bool值得表达式
- for循环的第二种使用方式
for 循环判断条件 { |
- for循环的第三种使用方式
for { |
Golang提供for-range的方式,可以方便遍历字符串和数组
注意:for-range在遍历字符串时,是按照字符来遍历的,而不是按照字节来的
var str string = "hello,world!" |
- 中文乱码问题:如果字符串含有中文,传统的遍历方式就是错误的,会出现乱码。传统的字符串遍历是按照字节遍历的,而中文在UTF-8中一个字为三个字节。解决方式:将 str 转成 []rune切片
- 对于for-range遍历方式而言,是按照字符方式便利。因此如果字符串有中文,也是可以正常遍历的
while和do…while的实现
Go语言中没有while和do…while的语法,这一点需要注意,如果我们需要使用类似其他语言(例如jav/c的while的do…while),可以通过for循环来实现其使用效果
//while使用for循环实现 |
多重循环控制
基本介绍:
- 将一个循环放在另一个循环体内,就形成了循环嵌套。在外边的for称为外层循环,在里面的for称为内层循环
- 实质上,嵌套循环就是把内层循环当成外层循环的循环体。当只有内层循环的循环条件为false时,才会跳出内层循环,才可结束外层循环的当次循环,开始下一次的循环
- 设外层循环次数为m次,内层循环为n次,则内层循环实际上需要执行m*n次
跳转控制语句
Break
package main |
break用于终止某个语句块的执行,用于中断当前for循环或跳出switch语句
//基本语法 |
说明:
- 说明语句块中,可以通过标签指明要终止的是哪条语句块
- 标签基本使用
label1 { |
continue
- continue语句用于结束本次循环,继续执行下一次循环
- continue语句出现在多层循环语句体中时,可以通过标签指明要跳转的是哪一层循环,这个和前面break的标签使用方法一致
{ |
//从键盘输入一个整数,判断这个数正数还是负数,最终输出正数与负数的个数 |
goto
- Go语言的goto语句可以无条件的转移到程序中指定的行
- goto语句通常与条件语句配合使用。可用来使用条件跳转,跳出循环体等功能
- 在Go程序设计中一般不主张使用goto语句,以免造成程序流程的混乱,是理解和调试程序都产生困难
return
return使用在方法或者函数中,表示跳出所在方法或函数,详见函数章节
- 如果return在一般函数中,则跳出该函数
- 如果return在main函数中,则退出程序
函数和方法
为什么需要函数?
- 函数可以解决模块化编程
- 函数可以减少代码冗余
为了完成某一功能的程序指令(语句)的集合,称为函数。
在Go语言中,函数分为:自定义函数、系统函数(查看Go编程手册)
函数的定义
//函数的基本语法 |
- 形参列表:表示函数的输入
- 函数中的语句:表示为了实现某一功能代码块
- 函数可以有返回值,也可以没有
package main |
包的介绍
在实际的开发中,我们往往需要在不同文件中,去调用其他文件的定义的函数,比如main.go中使用utils.go文件中的函数
基本介绍:Go的每一个文件都属于一个包,也就是说Go是以包的形式来管理文件和项目目录结构的
包的三大作用:
- 区分相同名字的函数、变量等标识符
- 当程序文件很多时,可以很好的管理项目
- 控制函数、变量等访问范围,即作用域
包的相关说明:
打包的基本语法:package 包名
引入包的基本语法:import “包的路径”
注意事项和使用细节:
- 在给一个文件打包时,该包对应一个文件夹,比如utils文件夹对应的包就是utils,文件的包名通常和文件所在的文件夹名一致,一般为小写字母。当一个文件要使用其他包函数或变量时,需要新引入对应的包。package指令在文件第一行,然后是import指令。在import包时,路径从GoPath的src下开始,不用带src,编译器会自动识别
- 为了让其他包的文件可以访问到本包的函数,则该函数名的首字母需要大写,类似其他语言的public,这样才能跨包使用
- 在访问其他包函数时,其语法是包名.函数名
- 如果包名较长,Go支持给包取别名,但取别名后原包名就不能使用了
- 在同一包下,不能有相同的函数名,否则报重复定义错误
- 如果编译一个可执行文件,就需要将这个包声明为main,即package main,如果写的是一个库,包名可以自定义
函数-调用机制
栈区:基本数据类型一般分配到栈区,编译器存在一个逃逸分析
堆区:引用书序类型一般分配在堆区,编译器存在一个逃逸分析
代码区:代码本身一般存放在代码区
在调用一个函数时,会给该函数分配一个新的空间,编译器会通过自身的处理让这个新空间和其他的栈的空间区分开来
每个函数对应的栈中,数据空间是独立的,不会混淆
当一个函数执行完毕后,程序会销毁函数对应的栈空间
return语句
//return基本语法 |
- 如果返回多个值时,在接受时,希望忽略某个返回值,则使用 _ 符号表示占位忽略
- 如果返回值只有一个,(返回值类型列表)中的( )可以不写
函数的递归调用
基本介绍:一个函数体内有调用了本身称为递归调用
package main |
函数递归调用需要遵循的重要原则
- 执行一个函数时,就创建一个新的受保护的独立空间(新函数栈)
- 函数的局部变量是独立的,不会相互影响
- 递归必须向退出递归的条件逼近,否则就会无限递归
- 当一个函数执行完毕,或者遇到return,就会返回。遵守谁调用,就将结果返回给谁。但函数执行完毕时,该函数本身也被销毁
package main |
注意事项和使用细节:
- 函数的形参列表可以是多个,返回值列表也可以是多个
- 形参列表和返回值列表的数据类型可以是值类型和引用类型
- 函数的命名遵循标识符命名规范,首字母不能是数字,首字母大写该函数可以北本包文件和其他包文件使用,首字母小写只嗯呢该本包文件使用
- 函数中的变量是局部的,函数外不生效
- 基本数据类型和数组默认都是值传递,即进行值拷贝。函数内修改不会影响原来值
- 如果希望函数内的变量能修改函数外的变量,可以**传入变量的地址&**,函数内以指针的方式操作变量,从效果上看类似引用
- Go函数不支持重载
- 在Go中,函数也是一种数据类型,可以赋值给一个变量,则该变量就是一个函数类型的变量了。通过该变量可以对函数调用
func getSum(n1 int, n2 int) int { |
函数既然是一种数据类型,因此在Go中,函数可以作为形参,并且调用
为了简化数据类型定义,Go支持自定义数据类型
基本语法:type 自定义数据类型名 数据类型
相当于一个别名。取别名之后,Go会认为别名和原名是不同的类型
支持函数返回值命名
使用 _ 标识符,忽略返回值
Go支持可变参数
//支持0到多个参数 |
init函数
基本介绍:每一个源文件都可以包含一个init函数,该函数会在main函数执行前,被Go运行框架调用,也就是说init会在main函数前被调用
注意事项和使用细节:
- 如果一个文件同时包含全局变量定义,init函数和main函数,则执行流程是变量定义、init函数、main函数
- init函数最主要的作用是,就是完成一些初始化工作
- main.go和utils.go中都有全局变量定义和init函数,则首先执行utils中的变量定义、init函数;其次执行main中的变量定义、init函数、main函数
匿名函数
基本介绍:Go支持匿名函数,如果某个函数只希望使用一次,可以考虑使用匿名函数,匿名函数也可以实现多次调用
匿名函数使用方式:
- 在定义匿名函数时就直接调用
- 将匿名函数赋给一个变量(函数变量),在通过该变量来调用匿名函数
全局匿名函数:如果将匿名函数赋给一个全局变量,那么这个匿名函数就成为一个全局匿名函数,可以在程序有效
闭包
基本介绍:闭包就是一个函数和与其相关的引用环境组合的一个整体(实体)
package main |
var n int = 10 |
类似面向对象:闭包是一个类,函数时操作,n时字段。函数和它使用到的n构成闭包
当我们反复调用f函数时,因为n只初始化一次,因此没调用一次就进行累加
闭包的关键,分析出返回的函数它使用(引用)哪些变量,函数和它引用的变量共同构成闭包
//编写一个函数makeSuffix(suffix string)接收一个文件后缀名,并返回一个闭包 |
函数中——defer
基本介绍:在函数中,程序员经常需要创建资源(比如:数据库连接、文件句柄、锁等),为了在函数执行完毕后,及时的释放资源,Go的设计者提供defer(延迟机制)
当执行到defer时,暂时不执行,会将defer后面的语句压入到独立栈(defer栈)
当函数执行完毕后,再执行defer栈中语句。按在先入后出的方式执行
package main |
注意事项和使用细节:
- 当Go执行到一个defer时,不会立即执行defer后的语句,而是将defer后的语句压入一个栈中,然后继续执行函数下一个语句
- 当函数执行完毕后,在从defer栈中,依次从栈顶取出语句执行(遵循栈先入后出原则)
- 在defer将语句放到栈时,也会将相关的值拷贝同时入栈
函数参数的传递方式
基本介绍:值类型参数默认就是值传递,而引用类型参数默认就是引用传递
两种传递方式:值传递、引用传递
无论是值传递还是引用传递,传递给函数的都是变量的副本。不同的是,值传递的是值的拷贝,引用传递的是地址的拷贝,一般来说,地址拷贝效率高,因为数据量小;而值拷贝由拷贝数据大小决定,数据越大效率越低
- 值类型:基本数据类型int系列、float系列、bool、string、数据、结构体
- 引用类型:指针、slice切片、map、管道chan、interface等都是引用类型
值传递和引用传递使用特点:
- 值类型默认是值传递:变量直接存储值,内存通常在栈中分配
- 引用类型默认是引用传递:变量存储的是一个地址,这个地址对应的空间才是真正的存储数据(值),内存通常在堆上分配,当没有任何变量引用这个地址时,该地址对应的数据空间就成为一个垃圾,由GC来回收
- 如果希望函数内的变量能修改函数外的变量,可以传入变量的地址&,函数内以指针的方式操作变量
变量作用域
基本介绍:
函数内部声明/定义的变量叫局部变量,作用域仅限于函数内部
函数外部声明/定义的变量叫全局变量,作用域在整个包都是有效的,如果首字母大写,则作用域在整个程序有效
如果变量是在一个代码块,比如for/if中,那么这个变量的作用域就在该代码块
函数体外不可以执行:Name := “tom”,因为这句话为两句合并而成
var Name string
Name = “tom” //会报错
字符串中常用的系统函数
基本介绍:字符串在我们日常程序开发中使用的非常多,Go语言为我们准备了常用函数
- 统计字符串的长度,按字节len(str)
str := "hello西安" |
- 字符串遍历,同时处理有中文的问题r := []rune(str)
str2 := []rune(str) // 转成切片 |
字符串转整数: n,err := strconv.Atoi(“12”)
整数转字符串: str = strconv.Itoa(12345)
n, err := strconv.Atoi("123") |
- 字符串转[]byte:var bytes = []byte(“hello go”)
var bytes = []byte("hello go") // 对应的ascii编码 |
- []byte转字符串:str = string([]byte{97,98,99})
str := string([]byte{97, 98, 99}) |
- 10进制转2、8、16进制:str = strconv.FormatInt(123,2)
str := strconv.FormatInt(123, 2) |
- 查找子串是否在指定字符串中:strings.Contains(“seafood”,”foo”)
b := strings.Contains("seafood", "foo") |
- 统计一个字符串有几个指定子串:strings.Count(“ceheese”,”e”)
b := strings.Count("ceheese", "e") |
不区分大小写的字符串比较:fmt.Println(strings.EqualFold(“abc”,”Abc”))
两个等号区分大小写
fmt.Println(strings.EqualFold("abc", "Abc")) |
返回子串在字符串第一次出现的index,如果没有返回-1:strings.Index(“NLT_abc”,”abc”)
如果主串中有多个子串字符,则返回第一个
index := strings.Index("NLT_abc", "abc") |
- 返回子串在字符串最后一次出现的index,如果没有返回-1:strings.LastIndex(“go golang”,”go”)
index := strings.LastIndex("go golang", "go") |
- 将指定的子串替换成另一个子串:strings.Replace(“go go hello”,”go”,”go语言”,n)n可以指定你希望替换的几个,如果n=-1表示全部替换
result := strings.Replace("go go golang", "go", "go语言", 1) |
- 按照指定的某个字符,为分割标识,将一个字符串拆分成字符串数组:strings.Split(“hello,world,ok”, “,”)
result := strings.Split("hello,world,ok", ",") |
- 将字符串的字母进行大小写的转换:strings.ToLower(“Go”)//go strings.ToUpper(“Go”)
str := "goLang Hello" |
- 将字符串左右两边的空格去掉:strings.TrimSpace(“ tn a lone gopher ntrn “)
result := strings.TrimSpace(" tn a lone gopher ntrn ") |
将字符串左右两边指定字符去掉:strings.Trim(“! hello! “, “ !”)
将字符串左边指定字符去掉:strings.TeimLeft(“! hello! “,” !”)
将字符串右边指定字符去掉:strings.TeimRight(“! hello! “,” !”)
result := strings.Trim("! hello! ", " !") |
- 判断字符串是否一指定的字符串开头:strings.HasPrefix(“ftp:198.168.10.1”,”ftp”)
- 判断字符串是否一指定的字符串结束:strings.HasSuffix(“NLT_abc.jpg”,”abc”)
result := strings.HasPrefix("ftp:198.168.10.1", "ftp") |
时间和日期相关函数
基本介绍:在编程中,程序员会经常使用到日期相关的函数,比如:统计某段代码执行话费的时间等
- 时间和日期相关函数,需要引入time包
- 获取当前时间now := time.Now()
result := time.Now() |
- 如何获取其他日期信息
fmt.Printf("年 = %v\n", result.Year()) |
- 格式化日期时间
fmt.Printf("当前年月日:%d-%d-%d %d:%d:%d", result.Year(), result.Month(), result.Day(), result.Hour(), result.Minute(),result.Second()) |
fmt.Printf(result.Format("2006/01/02 15:04:05"))//输入内容固定 |
时间的常量
常量的作用:在程序中可用于获取指定时间单位的时间,比如100毫秒
Hour、Minute、Secon、Millisecond、Microsecond、Nanosecond
休眠:time.Sleep(100 * time.Millisecond)
Unix时间戳和Unixnano时间戳(可以获取随机数字)
now := time.Now() |
package main |
内置函数
基本介绍:Golang设计者为了编程方便,提供了一些函数,这些函数可以直接使用,我们称为Go的内置函数
- len:用来求长度,比如string、array、slice、map、channel
- new:用来分配内存,主要用来分配值类型,比如int、float32、struct…返回是指针
- make:用来分配内存,主要用来分配引用类型,比如map、chan、slice
Go错误处理机制
- 在默认情况下,当发生错误后(panic),程序就会退出(崩溃)
- 如果希望,当发生错误后我们可以捕获该错误,并进行处理,保证代码可以继续执行,还可以在捕获错误后给管理员一个提示(邮件、短信)
基本介绍:
- Go语言主球简洁优雅,所以Go语言不支持传统的try…catch…finally这种处理
- Go中引入的处理方式为:defer,panic,recover
- 这几个异常的使用场景可以这么简单描述:Go中可以抛出一个panic的异常,然后再defer中通过recover捕获这个异常,然后正常处理
defer func(){ |
错误处理的好处:进行错误处理后,程序不会轻易挂掉,如果加入预警代码,就可以让程序更加的健壮
自定义错误
Go程序中,也支持自定义错误,使用erroes.New和panic内置函数
- errors.New(“错误说明”),会返回一个error类型的值,表示一个错误
- panic内置函数,接收一个interface{}类型的值(也就是任何值)作为参数。可以接收error类型的变量,输出错误信息并退出程序
package main |
数组和切片
数组介绍
基本介绍:数组可以存放多个同一种类型数据。数组也是一种数据类型,在Go中数组是值类型
package main |
使用数组来解决问题,程序的可维护性增加了,代码清晰容易扩展
数组定义和内存布局
//数组定义: |
当定义完数组之后,数组就有默认值,为0
内存布局:
- 数组的地址可以通过数组名获取
- 数组的第一个元素的地址是数组的首地址
- 数组的内存是连续分布
- 数组元素间隔取决于数组类型
package main |
数组初始化的四种方式:
- var nums [3]int = [3]int {1, 2, 3}
- var nums = [3]int {1, 2, 3}
- var nums = […]int {1, 2, 3} //这里的…是固定写法
- var names = [3]string{1:”tom”, 0:”jack”, 2:”marry”}
数组遍历
基本介绍:
方式一:常规遍历方式,通过for循环,遍历数组下标
方式二:for-range结构
for index, value :=range array01 { //array01为数组名称 |
注意事项和使用细节:
- 第一个返回值index是数组下标
- 第二个返回值value是在该下标位置的值
- 两个返回值都是仅在for循环内部可见的局部变量
- 遍历数组元素的时候,如果不想使用下标index,可以把下标index标为下划线_
- index和value的名称不是固定的,即程序员可以自行指定,一般命名为index和value
数组使用
注意事项和使用细节:
数组是多个同类型数据的组合,一个数组一旦声明/定义了。其长度是固定的,不能动态变动
var arr []int这是arr就是一个slice切片,详见切片章节
数组中的元素可以是任何数据类型,包括值类型和引用类型,但不能混用
数组创建后,如果没有赋值,含有默认值
数值类型数组,默认值为0
字符串类型数组,默认值为””
bool类型数组,默认值为false
使用数组步骤:
- 声明数组并开辟空间
- 给数组各个元素赋值
- 使用数组
数组的下标是从0开始的
数组下标必须在指定范围内使用,否则报panic:数组越界
Go的数组属值类型,在默认情况下是值传递
如果想在其他函数中,去修改原来的数组,可以使用引用传递(指针方式)
长度是数组类型的一部分,在传递函数参数时需要考虑数组长度
slice切片
当我们需要保存个数不确定的数据
基本介绍:
切片是数组的一个引用,因此切片是引用类型,在进行传递,遵守引用传递的机制
切片的使用和数组类似,遍历切片、访问切片的元素和求切片长度len(slice)一样
切片长度是可以变化的,因此切片是一个可以动态变换数组
切片定义的基本语法:
var 变量名 []类型
var intArr [5]int = [...]int{1, 2, 3, 4, 5} |
切片在内存中形式:
切片为引用类型,在内存中,slice由三个部分构成:
首先,slice存放指向的首地址,&slice[0] = &intArr[1],slice[0] = intArr[1]
其次,存放slice的长度
最后,存放slice的容量
//slice从底层上说就是一个结构体 |
切片使用方式
方式一:定义一个切片,然后让切片引用一个已经创建好的数组
方式二:通过make来创建切片
var 切片名 []type = make ([],len,cap)
type:数据类型;len:大小;cap:容量。cap可以不写,但如果写了需要大于len
var slice []float64 = make([]float64, 5, 10) |
- 通过make方式创建切片可以指定切片的大小和容量
- 如果没有给切片的各个元素赋值就会使用默认值
- 通过make创建的切片对应的数组室友make底层维护,对外不可见,只能通过slice访问切片
方式三:定义一个切片,直接就指定具体数组,使用原理类似make的方式
var slice []string = []string{"tom", "jack", "marry"} |
切片使用方式的区别:
方式一是直接引用数组,这个数组是事先存在的,程序员是可见的
方式二是通过make来创建切片,make也会创建一个数组,是有切片在底层进行维护,程序员无法看见
切片遍历
切片遍历和数组遍历类似,可以通过for循环进行遍历,也可以通过for-range结构进行遍历
var arr [5]int = [...]int{10, 20, 30, 40, 50} |
注意事项和使用细节:
切片初始化时var slice = arr[startIndex:endIndex]
从arr数组下标为startIndex,取到下标endIndex的元素(不包含endIndex)
切片初始化时,仍然不能越界。范围在[0-len(slice)],到那时可以动态增长
var slice = arr [0:end] 可以简写为 var slice = arr[:end]
var slice = arr[start:len(arr)] 可以简写为 var slice = arr[start:]
var slice = arr[0:len(arr)] 可以简写为 var slice = arr[:]
cap是一个内置函数,用于统计切片的容量,即最大可以存放多少个元素
切片定义完后,还不能使用,因为本身是一个空的,需要让其引用到一个数组,或者make一个空间供切片来使用
切片可以继续切片
用append内置函数,可以对切片进行动态追加
切片append操作的本质就是对数组扩容
go底层会闯将一下新的数组newArr(安装扩容后大小)
将slice原来包含的元素拷贝到新的数组newArr
slice重新引用到newArr
注意newArr是在底层来维护的
var slice []int = []int{1, 2, 3} |
- 切片的拷贝操作
var a []int = []int{1, 2, 3, 4, 5} |
- 切片时引用类型,所以在传递时,遵循引用传递机制
string和slice
string底层是一个byte数组,因此string也可以进行切片处理
string和切片在内存的形式
string是不可变的,也就是说不能通过str[0] = ‘z’方式来修改字符2
如果需要修改字符串,可以先将string->[]byte或**[]rune**->修改->重写转成string
str := "hello@atguigu" |
//中文替换 |
//使用切片输出斐波那契数 |
二维数组
使用方式:先声明/定义再赋值
//语法 |
二维数组遍历:
- 双层for循环完成遍历
- for-range方式完成遍历
map
map是kay-value数据结构,又称为字段或者关联数组。类似其他编程语言的集合,在编程中经常用到
//基本语法 |
key可以是什么类型:
Golang中map的key可以时很多类型,例如:bool、数字、string、指针、channel,还可以是只包含前面几个类型的接口、结构体、数组,通常为int、string
注意:slice、map和function是不可以的
valuetype可以是什么类型:
valuetype的类型和key基本一样,通常为数字(整数、浮点数)、string、map、struct
//map的声明 |
package main |
map的使用方式
- 方式一:
//声明,这时map=nil |
- 方式二:
//声明,直接make |
- 方式三:
//声明,直接赋值 |
map使用前一定要make
map的增删改查
- 增加和更新:
map["key"] = value //如果key不存在就是增加,如果key存在就是修改 |
- 删除
//仅需删除cities中一个元素时 |
- 查找
//返回ok为bool类型,val为值类型 |
map遍历
map的遍历使用for-range的结构遍历,无法使用for循环
for k, v := range cities { |
map切片
基本介绍:切片的数据类型如果是map,则我们称为slice of map,map切片,这样使用则map个数就可以动态变化了
package main |
map排序
基本介绍:
- Golang中没有一个专门的方法针对map的key进行排序
- Golang中的map默认是无序的,注意也不是按照添加的顺序存放的,每次遍历的输出可能不一样
- Golang中map的排序,是先将key进行排序,然后根据key值遍历输出
Golang中map中排序:
- 先将map的key放到切片
- 对切片排序
- 遍历切片,然后按照key来输出map的值
package main |
map的使用细节和陷阱
注意事项和细节说明:
- map是引用类型,遵守引用类型传递机制,在一个函数接收map修改后,会直接修改原来的map
- map的容量达到后,如果希望map增加元素会自动扩容,并不会发生panic,map能动态的增长键值对(key-value)
- map的value也经常使用struct类型,更适合管理复杂的数据(比前面的value是一个map更好)
package main |
面向”对象“编程
Golang语言面向对象编程说明:
- Golang也支持面向对象编程(OOP),但是和传统的面向对象编程有区别,并不是纯粹的面向对象语言。所以我们说Golang支持面向对象编程特性是比较准确地
- Golang没有类(class),Go语言的结构体(struct)和其他编程语言的类(class)有同等的地位,可以理解Golang是基于struct来实现OOP特性的
- Golang面向对象编程非常简洁,去掉了传统OOP语言的继承、方法重载、构造函数和析构函数、隐藏的this指针等等
- Golang仍然有面向对象编程的继承性,封装和多态的特性,只是实现方式和其他OOP语言不一样。例如继承:Golang没有extends关键字,继承通过匿名字段来实现
- Golang面向对象(OOP)很优雅,OOP本身就是语言类型系统(type system)的一部分,通过接口(interface)关联,耦合性低,也非常灵活。也就是说Golang中面向接口编程是非常重要的特性
结构体
结构体与结构变量(实例/对象)
- 将一类事物的特性提取出来,形成一个新的数据类型,就是结构体
- 通过这个结构体我们可以创建多个变量
package main |
- 结构体是自定义的数据类型,代表一类事物
- 结构体变量(实例)是具体的、实际的,代表一个具体变量
结构体是一个值类型
结构体声明和是用缺陷
//结构体声明 |
基本介绍:
- 从概念或叫法上看:结构体字段 = 属性 = field
- 字段是结构体的一个组成部分,一般是基本数据类型、数组,也可以是引用类型
注意事项和使用细节:
- 字段声明语法同变量
- 字段的类型可以为:基本类型、数组或引用类型
- 创建一个结构体变量后,如果没有给字段赋值,都对应一个零值(默认值)
- 不同结构体变量的字段是独立的,互补影响的,一个结构体变量字段的更改不影响另一个
如果结构体字段类型是slice和map的零值都是nil,即未分配空间。如果需要使用这样的字段需要先make在使用
创建结构体变量和访问结构体字段
type Person struct { |
基本介绍:
- 第三种和第四种返回的是结构体指针
- 结构体指针访问字段的标准方式应该是:**(结构体指针).字段名*
- Go做出了简化,支持结构体指针.字段名
注意事项和使用细节:
- 结构体的所有字段在内存中是连续的
- 结构体是用户单独定义的类型,和其他类型进行转换时需要完全相同的字段
- 结构体进行type重新定义(相当于取别名),Golang认为是新的数据类型,但是相互可以强制转换
- struct的每个字段上,可以写一个tag,该tag可以通过反射机制获取,常见的使用场景就是序列化和发序列化
方法
基本介绍:在某些情况下,我们需要声明(定义)方法。比如Person结构体:除了一些字段外(年龄、姓名…),Person结构体还有一些行为比如:可以说话、跑步…
//方法的声明和调用 |
package main |
- test方法和Person类型绑定
- test方法只能通过Person类型的变量来调用,而不能直接调用,也不能使用其他类型变量来调用
- func (p Person) test(){}… p类似于函数传参,p名字可以修改
方法的调用和传参机制和函数基本一样,不一样的地方是方法调用时,会将调用方法的变量,当做实参也传递给方法
方法的声明(定义)
func (recevier type) methodName (参数列表) (返回值列表) { |
基本介绍:
- 参数列表:表示方法输入
- recevier type:表示这个方法和type这个类型进行绑定,或者说该方法作用于type类型
- receiver type:type可以是结构体也可以是其他的自定义类型
- recriver type:就是type类型的一个变量(实例),比如:Person结构体的一个变量(实例)
- 返回值列表:表示返回的值,可以多个
- 方法主体:表示为了实现某一功能代码块
- return 语句不是必须的
注意事项和使用细节:
- 结构体类型是值类型,在方法调用中,遵守值类型的传递机制,是值拷贝传递方式
- 如程序员希望在方法中修改结构体变量的值,可以通过结构体指针的方式来处理
- Golang中的方法作用在指定的数据类型上的(即:和指定的数据类型绑定),因此自定义类型都可以有方法,而不仅仅是struct
- 方法的访问范围控制的规则,和函数一样,方法名首字母小写,只能在本报包访问;方法首字母大写,可以在本包和其他包访问
- 如果一个类型实现String()这个方法,那么fmt.Println默认会调用这个变量的String()进行输出
方法和函数区别
调用方式不一样
函数调用方式:函数名(实参列表)
方法调用方式:变量.方法名(实参列表)
对于普通函数,接受者为值类型时,不能将指针类型的数据直接传递,反之亦然
对于方法(如struct的方法),接受者为值类型时,可以直接用指针类型的变量调用方法,反过来也可以接收。具体类型看方法的接收类型
package main |
面向对象编程应用
面向对象步骤
- 声明(定义)结构体,确定结构体名
- 编写结构体的字段
- 编写结构体的方法
结构体赋值
- 在创建结构体变量时,就直接指定字段的值。将字段名和字段值写在一起,不依赖与顺序
- 返回结构体的指针类型
工厂模式
使用工厂模式实现挎包创建结构体实例(变量)
如果model包的结构体变量首字母大写,引入后可直接使用
如果model包的结构体变量首字母小写,可使用工厂模式解决
在model包中创建一个方法或函数,从而调用
面向对象编程思想-抽象
如何理解抽象:我们在前面去定义一个结构体时候,实际上就是把一类事物的共有的属性(字段)和行为(方法)提取出来,形成一个物理模型(模板)。这种研究问题的方法称为抽象
面向对象编程的三大特性(封装、继承、多态)
基本介绍:Golang仍然有面向对象编程的继承,封装和多态的特性,只是实现的方式和其他OOP语言不太一样
封装
封装介绍:封装(encapsulation)就是把抽象出的字段和对字段的操作封装在一起,数据被保护在内部,程序的其他包只通过被授权的操作(方法),才能访问字段进行操作
封装的好处:
- 隐藏实现细节
- 提可以对数据进行验证,保证安全合理
如何体现封装:
- 对结构体中的属性进行封装
- 通过方法、包实现封装
封装的实现步骤:
- 将结构体、字段(属性)的首字母小写(不能导出了,其他包不能使用,类型private)
- 给结构体所在包提供一个工厂模式的函数,首字母大写。类似构造函数
- 提供一个首字母大写的Set方法(类似其他语言的public),用于对属性判断并赋值
func (var 结构体类型名) SetXxx(参数列表)(返回值列){ |
- 提供一个首字大写的Get方法(类似其他语言的public),用于获取属性的值
func (var 结构体类型名) GetXxx(){ |
//案例演示 |
package model |
继承
继承介绍:继承可以解决代码复用,让我们编程思维更加靠近人类思维
当多个结构体存在相同的属性(字段)和方法时,可以从这些结构体中抽象出结构体,在该结构体中定义这些相同的属性和方法
其他结构体不需要重新定义这些属性和方法,只需要嵌套一个匿名结构体即可
//嵌套匿名结构体的基本语法 |
说明:
- 结构体可以使用嵌套匿名结构体所有的字段和方法,即:首字母大写或者小写的字段和方法都可以使用
- 匿名结构体字段访问可以简化
- 当结构体和匿名结构体有相同的字段或者方法时,编译器采用就近访问原则访问,如希望访问匿名结构体的字段和方法,可以通过匿名结构体来区分
- 结构体中嵌入了两个或多个匿名结构体,如两个匿名结构体有相同的字段和方法(同时结构体本身没有同名的字段和方法),在访问时就必须明确指定匿名结构体名字,否则编译器报错
- 如果一个结构体嵌套一个有名的结构体,这种模式就是组合,如果是组合关系,那么在访问组合的结构体字段或方法时,必须带上结构体名字
- 嵌套匿名结构体后,也可以在创建结构体变量(实例)时,直接指定各个匿名结构体字段的值
多重继承说明:
- 如果一个结构体嵌套了多个匿名结构体,那么该结构体可以直接访问嵌套的匿名函数结构体的字段和方法,从而实现多重嵌套
- 如嵌入的匿名结构体有相同的字段名或者方法名,在访问时需要通过匿名结构体的类型名来区分
- 为了保证代码的简洁性,建议不要使用多重继承
接口(interface)
在Golang中多态特性主要是通过接口实现的
package main |
接口介绍:interface类型可以定义一组方法,但是这些不需要实现。并且interface不能包含任何变量。到某个自定义类型(比如结构体)要用的时候,再根据情况把这些方法写出来
//基本语法 |
使用说明:
- 接口里的所有方法都没有方法体,即接口的方法都是没有实现的方法。接口体现了程序设计的多态和高内聚低耦合的思想
- Golang中的接口不需要显式的实现。只要一个变量含有接口类型中的所有方法那么就这个变量就实现这个接口。因此,Golang中没有implement这样的关键字
注意事项和使用细节:
- 接口本身不能创建实例,但是可以指向一个实现了该接口的自定义类型的变量(实例)
- 接口中所有的方法都没有方法体,即都是没有实现的方法
- 在Golang中,一个自定义类型需要将某个接口的所有方法都实现,我们说这个自定义类型实现了该接口
- 一个自定义类型只有实现了某个接口,才能将该自定义类型的实例(变量)赋给接口类型
- 只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型
- 一个自定义类型可以实现多个接口
- Goalng接口不能有任何变量
- 一个接口可以继承多个别的接口,这是如果要实现该接口,就要将内部所有接口实现
- interface类型默认是一个指针类型(引用类型),如果没有对interface初始化就使用会输出nil
- 空接口interface{}没有任何方法,所以所有类型都是实现了空接口,可以把任何一个变量赋给空接口
//接口案例 |
接口和继承的区别
- 当A结构体继承了B结构体,那么A结构体就自动的继承了B结构体的字段和方法,并且可以直接使用
- 当A结构体需要扩展功能,同时不希望去破坏继承关系,则可以去实现某个接口即可,因此我们认为接口是对继承机制的补充
接口和继承解决的问题不同:
- 继承的价值主要在于:解决代码的复用性和可维护性
- 接口的价值主要在于:设计好各种规范(方法),让其他自定义类型去实现这些方法
接口比继承更加灵活
接口在一定程度上实现代码解耦
多态
基本介绍:变量(实例)具有多种形态。面向对象的第三大特性,在Go语言中,多态特征是通过接口实现的。可以按照统一的接口来调用不同的实现。这是接口变量就呈现不同的形态
接口体现多态特征:
- 多态参数:在前的Usb案例中,Usb usb,即可接收手机变量又可以接收相机变量,就体现了Usb接口的多态
- 多态数组:给定Usb数组存放Phone和Camera 结构体变量
类型断言
基本介绍:类型断言由于接口是一般类型,不知道具体类型,如果要转成具体类型,就需要使用类型断言
//如果我们希望将空接口类型重新转换为对应的类型,就需要使用到类型断言 |
带检测的类型断言
y, ok = x.(float64) |
类型断言的好处:如果转换出错不至于报panic,而是可以继续执行代码
//Phone、Camera案例,使用类型断言给phone加上call方法 |
文件操作
文件是数据源(保存数据的地方)的一种。文件最主要的作用就是保存数据,它即可以保存一张图片,也可以保存视频音频
文件在程序中是以流的形式来操作的
流:数据在数据源(文件)和程序(内存)之间经历的路径
输入流:数据从数据源(文件)到程序(内存)的路径
输出流:数据从程序(内存)到数据源(文件)的路径
os.File封装所有文件相关操作,File是一个结构体
常用的文件操作函数和方法
- 打开一个文件进行读操作:
os.Open(name string)(*File, error) |
- 关闭一个文件:
File.Close() |
读取文件
读取文件的内容并显示在终端(带缓冲区的方式),使用os.Open,file.Close,bufio.NewReader(),reader.ReadString函数和方法
package main |
- 读取文件的内容并显示在终端(使用ioutil一次性将整个文件读到内存中),这种方式适用于文件不大的情况。相关方法和函数ioutil.ReadFile
package main |
写文件操作
func OpenFile(name string, flag int, perm FileMode)(file *File, err error) |
说明:os.OpenFile是一个更一般性的文件打开函数,它会使用指定的选项(如O_RDONLY等)、指定的模式(如0666等)打开指定名称的文件。如果操作成功,返回的文件对象可用于I/O。如果出错,底层错位类型是*PathError
第二个参数:文件打开模式(可以组合):
const ( |
第三个参数:权限控制(Linux/Unix),在Windows在无效。详见Linux内容
r->4
w->2
x->1
判断文件是否存在
Golang判断文件或文件夹时候存在的方法为使用os.Stat()函数返回的错误值进行判断:
- 如果返回的错误值为nil,说明文件或文件夹存在
- 如果返回的错误值类型使用os.IsNotExist()判断为true,说明文件或文件夹不存在
- 如果返回的错误值为其他类型,则不确定是否存在
func PathExists(path string) (bool, error) { |
文件拷贝
func Copy(dst Writer, src Reader)(written int64, err error) |
package main |
统计在文件中的字符
package main |
命令行参数
os.Args是一个string切片,用来存储所有的命令行参数
package main |
flag解析命令行参数
说明:前面的方式比较原生的方式,对解析参数不是特别的方便,特别是带有指定参数形式的命令行
package main |
Json基本介绍
概述:JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。易于人的阅读和编写。同时也易于机器解析和生成
JSON实在2001年开始推广使用的数据格式,目前已经成为主流的数据格式
JSON易于机器解析和生成,并有效的提升网络的传输效率,通常程序在网络传输时会将数据(结构体、map等)序列化成json字符串,到接收方得到json字符串时再反序列化恢复成原来的数据类型(结构体、map等)。这种方式已然成为各个语言的标准
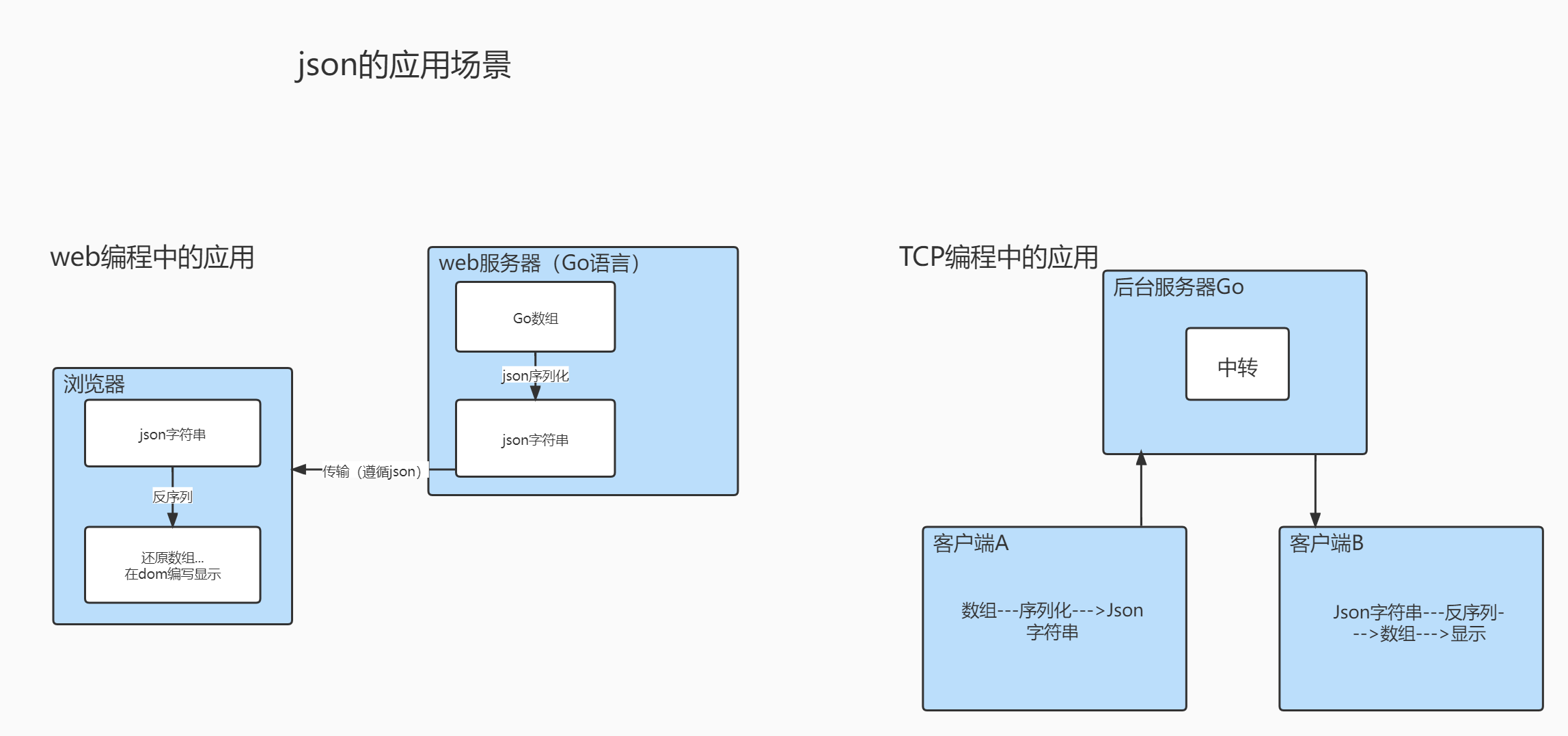
JSON数据格式
在JS语言中,一切都是对象。因此,任何的数据类型都可以通过JSON来表示,例如字符串、数字、对象、数字、mao等,任何数据类型都可以转成JSON
JSON键值对是用来保存数据一种方式,键/值对组合中的键名写在前面并用双引号””包裹,使用冒号:分隔,然后紧接着值
{ |
JSON序列化
json序列化是指将有key-value结构的数据类型(比如结构体、map、切片)序列化成json字符串的操作
json.Marshal() |
package main |
对基本数据类型数据化意义不大
JSON反序列化
json反序列化是指将json字符串反序列化成对应的数据类型(比如结构体、map、切片)的操作
json.Unmarshal() |
package main |
反序列化是map不需要make,反序列化封装至unmarshal函数
注意事项和使用细节:
- 反序列化后的数据类型要和序列化之前的数据类型一致
- 如果字符串时通过程序获得的,在反序列化是不需要对双引号进行转义处理
单元测试
传统方法:在main函数中调用函数,看看实际输出结果与预期结果是否一致
传统测试方法的缺点:
- 不方便,需要在主函数中调用。如果项目正在运行则可能停止项目
- 不利于管理,当我们需要测试多个模块式,都需要卸载main函数中】
基本介绍:Go语言中自带有一个轻量级的测试框架testing和自带的Go test命令来实现单元测试和性能测试,testing框架和其他语言中的测试框架类似,可以基于这个框架写针对相应函数的测试用例,也可以基于该框架写相应的压力测试用例
- 确保每个函数是可运行,并且运行结果是正确的
- 确保写出来的代码性能是好的
- 单元测试能及时的发现程序设计或实现的逻辑错误,使问题及时暴露,便于问题的定位解决,而性能测试的重点在于发现程序设计上的一些问题,让程序能够在高并发的情况下还能保持稳定
package main |
package main |
注意事项和使用细节:
- 测试用例文件名必须以**_test.go**结尾
- 测试用例函数必须以Test开头
- TestAddUpper(t *testing.T)的形参类型必须是 *testing.T
- 一个测试用例文件中,可以有多个测试用例函数
- cmd-> go test
- cmd->go test -v
- 当出现错误时,可以使用t.Fatalf来格式化输出错误信息
- t.LogF方法可以输出相应的日志
- 测试用例函数并没有放在主函数中执行,这就是测试用例的方便之处
- PASS表示测试用例运行成功,FAIL表示测试用例运行失败
- 测试单个文件一定要带上被测试的原文件(cmd)go test -v AddUpper_test.go AddUpper.go
- 测试单个方法go test -v-test.run TestAddUpper
GoRoutine和Channel
Goroutine
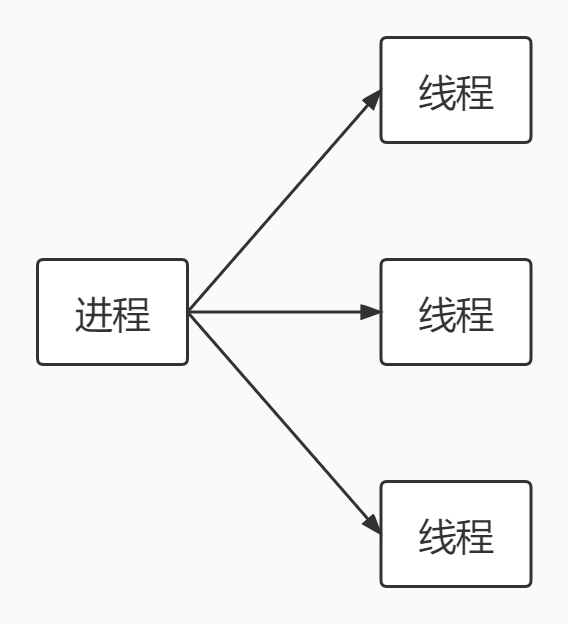
进程和线程说明:
- 进程就是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位
- 线程是进程的一个执行实例,是程序执行的最小单元,它是比进程更小的能独立运行的基本单元
- 一个进程可以创建和销毁多个线程,同一个进程中的多个线程可以并发执行
- 一个程序至少有一个进程,一个进程至少有一个线程
并发和并行:
- 多线程程序在单核上运行就是并发
- 多线程程序在多核上运行就是并行
并发特点:从微观角度看,在一个时间节点上实际只有一个任务在执行
Go协程和Go主线程
Go主线程(有程序员直接称为线程/也可以理解成进程):一个Go线程上可以起多个协程,协程是轻量级的线程
Go协程特点:
- 有独立的栈空间
- 共享程序堆空间
- 调度由用户控制
- 协程是轻量级线程
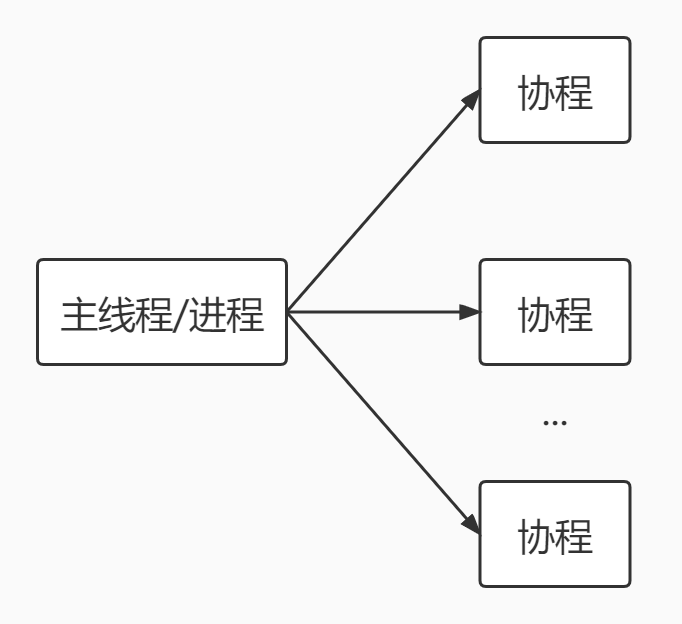
//使用主线程和协程并发输出内容 |
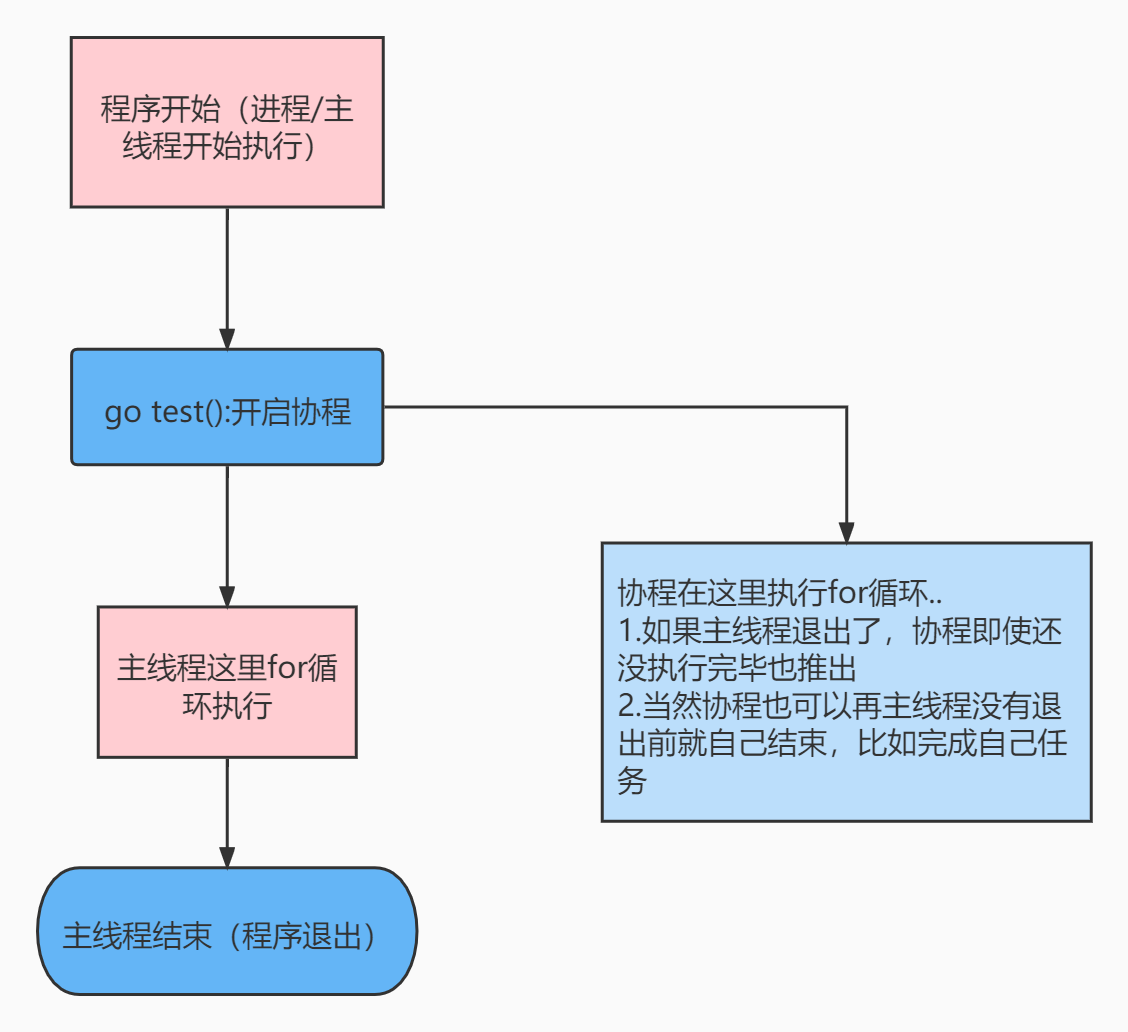
小结:
- 主线程是一个物理线程,直接作用在CPU上的。是重量级的,非常耗费CPU资源
- 协程从主线程开启,是轻量级的线程,是逻辑态。对资源消耗相对较小
- Golang的协程机制是重要的特点,可以轻松开启上万个协程。其他编程语言的并发机制是一般基于线程的,开启过多的线程,资源耗费大。就凸显了Golang的优势
MPG模式基本介绍
- M:操作系统的主线程(物理线程)(三角形)
- P:协程执行需要的上下文(四边形)
- G:协程(圆形)
状态1
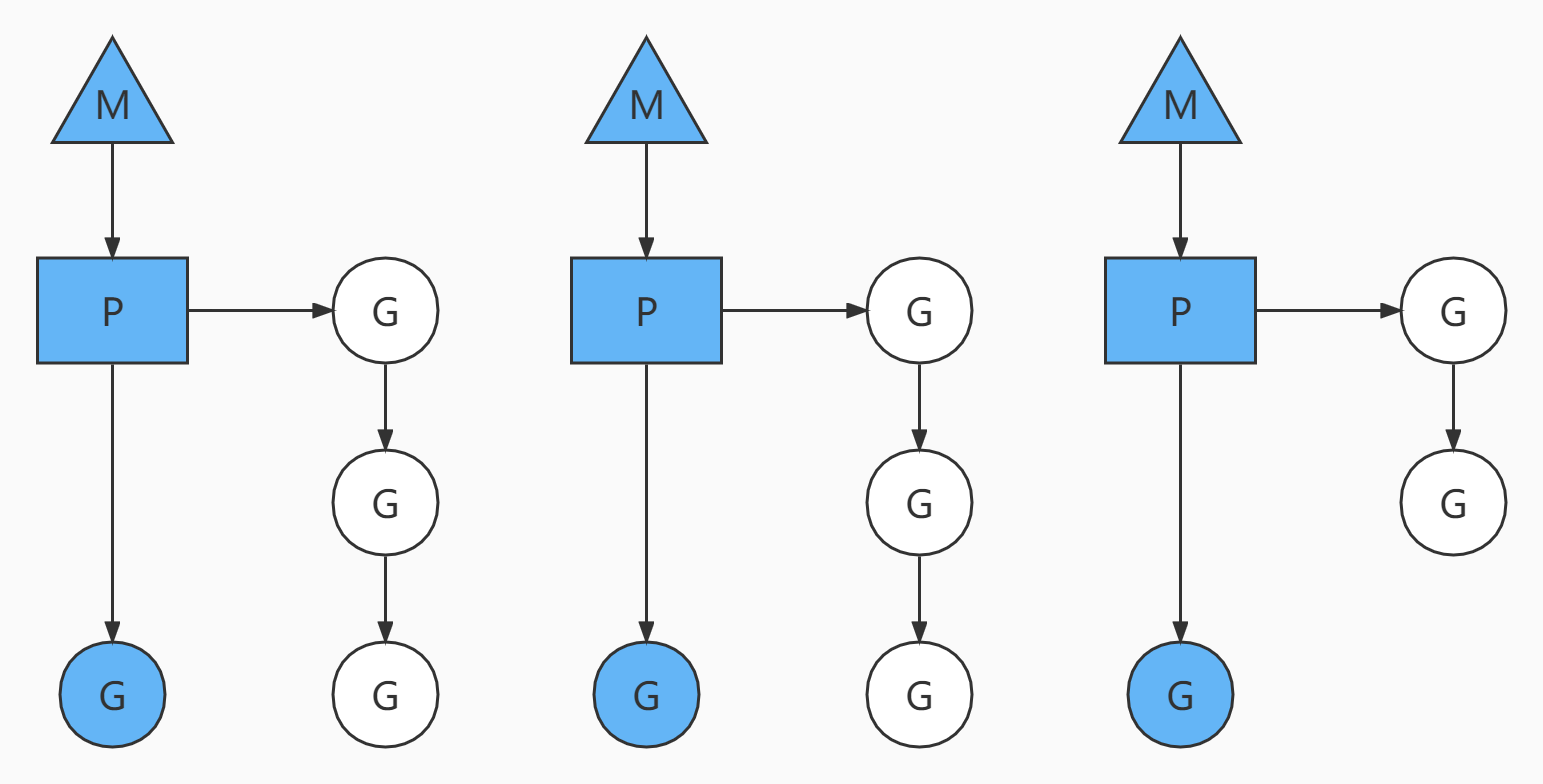
- 当前程序有三个M,如果三个M都在一个CPU上运行就是并发,如果在不同的CPU上运行就是并行
- M1,M2,M3正在执行一个G,M1的协程队列有三个,M2的协程队列有三个,M3的协程队列有两个
- 从图上可以看到:Go的协程是轻量级的线程,是逻辑态的,Go可以起上万个协程
- 其他程序C/Java的多线程,往往是内核态,比较重量级,几千个线程可能耗光CPU
状态2
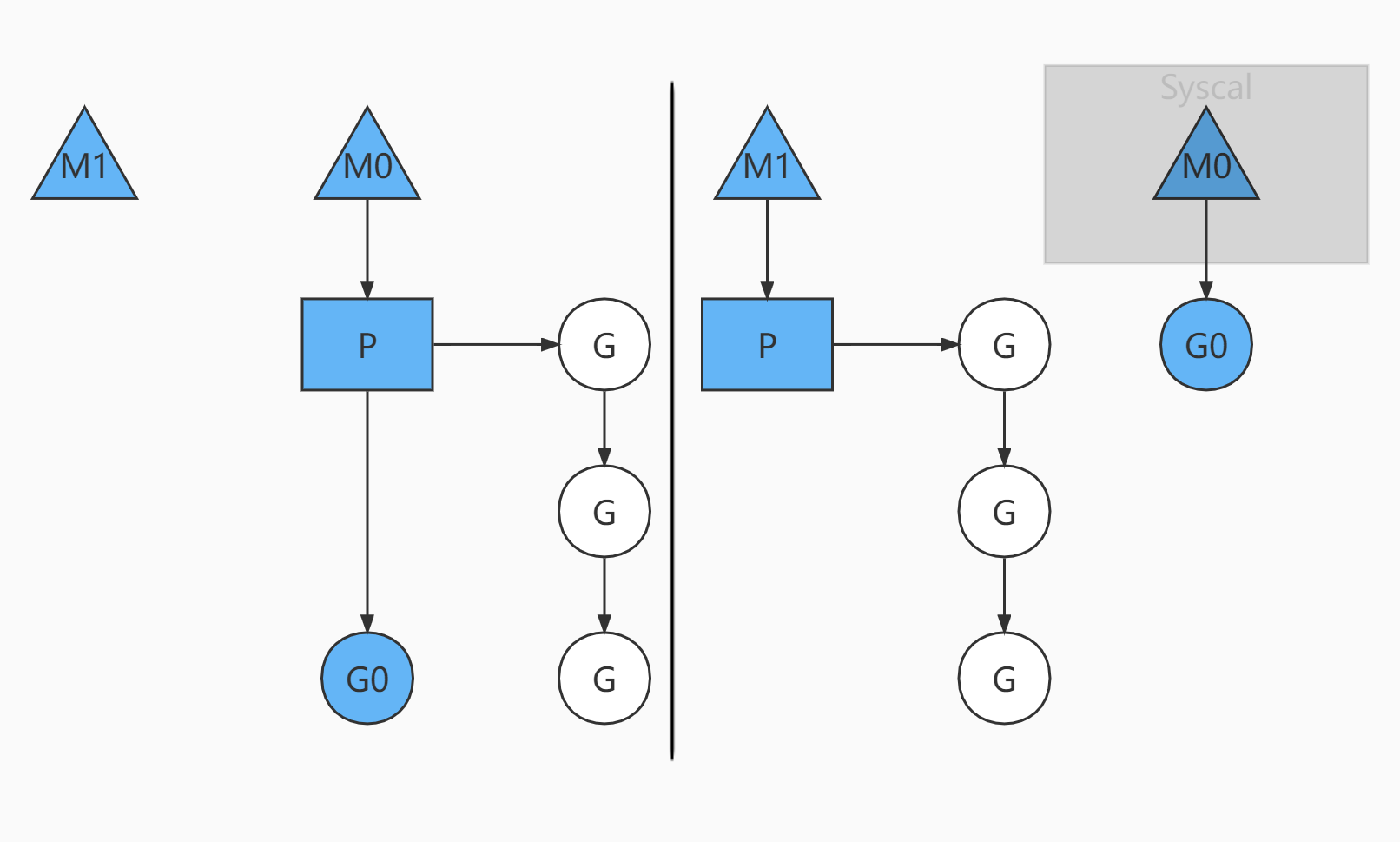
- 分为两个部分看
- 原来情况是M0主线程正在执行G0协程,另外三个协程在队列等待
- 如果G0协程阻塞,比如读取文件或数据库等
- 这时救赎创建M1主线程(也可能是从已有线程池中取出M1)。并且将等待的3个协程挂到M1下开始执行,M0的主线程下的G0仍然执行文件io的读写
- 这样的MPG调度模式,可以即让G0执行,同时也不会让队列的其他协程一直阻塞,仍然可以并发/并行执行
- 等到G0不阻塞了,M0会被放到空闲的主线程继续执行(从已有的线程池中取),同时G0又会被唤醒
Golang中设置运行CPU
import runtime |
Golang中并发(并行)引起的资源争夺问题
当我们使用Goroutine对全局变量进行写入操作时,如果协程较多导致多个协程同时访问某一全局变量资源时就会报错concurrent writes
解决方案:对全局变量加全局互斥锁访问sync.Mutex
//并发运算20以内数的阶乘并存入map中 |
Channel管道
为什么需要channel?
前面使用全局变量加锁同步来解决goroutine的通讯并不完美
- 主线程在等待所有goroutine全部完成的时间很难确定
- 如果主线程休眠时间长了,会加长等待时间;如果时间短了可能还有goroutine出于工作状态,这时也会随主线程的退出而销毁
- 通过全局变量加锁同步来实现通讯,也并没有利用多个协程对全局变量的读写操作
- 以上的需求引出新的通讯机制—channel
基本介绍:
- channel本质就是一个数据结构—队列
- 数据先进先出(FIFO)
- 线程安全,多goroutine访问是不需要加锁
- channel是有类型的,一个string的channel只能存放string
基本使用:
var 变量名 chan 数据类型 |
说明:
- channel是引用类型
- channel必须初始化才能写入数据,即make后才能使用
- 管道是有类型的,intChan只能写入整数int
package main |
注意事项和使用细节:
- channel中只能存放指定的数据类型
- channel的数据放满后就不能再放入
- 如果从channel取出数据后可以继续放入
- 在没有使用协程的情况下,如果channel数据取完再取就不报错(deed lock)
channel关闭
close(intChan) |
使用内置函数close可以关闭channel,当channel关闭后就不能再向channel写入数据,但是仍然可以从该channel中读取数据
channel遍历
channel支持for-range的方式进行遍历:
- 在遍历时,如果channel没有关闭,则回出现deadlock错误
- 在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后就会退出遍历
不可使用普通遍历方式
注意事项和使用细节:
- channel可以声明为只读,或者只写性质
var chan chan<- int//只写 |
- 使用select可以解决从管道取数据的阻塞问题
select{ |
goroutine中使用recover,解决协程出现panic,导致程序崩溃问题
说明:如果我们起一个协程,但是这个协程出现panic,如果我们没有捕获这个panic,就会造成程序崩溃,这是我们可以在goroutine中使用recover来捕获panic进行处理。这样及时协程发生问题但是主线程仍然不受影响,可以继续执行
反射
应用场景一:在Json序列化过程中,给结构体标签的应用
应用场景二:go框架的开发中,使用反射机制编写函数的适配器、桥连接
基本介绍:
- 反射可以在运行时动态获取变量的各种信息,比如变量的类型(type),类别(kind)
- 如果是结构体变量,还可以获取到接哦固体本身的信息(包括结构体的字段、方法)
- 通过反射,可以修改变量的值,可以调用关联的方法
- 使用反射,需要import(“reflect”)
反射重要的函数和概念:
- reflect.TypeOf(变量名),获取变量的类型,返回reflect.Type类型
- reflect.ValueOf(变量名),获取变量的值,返回reflect.Value类型,reflect.Value是一个结构体类型
- 变量、interface{}和reflect.Value是可以相互转换的
//专门用于作反射 |
注意事项和使用细节:
- reflect.Value.Kind,获取变量的类别,返回的是一个常量
- Type是类型,Kind是类别,Type可能是相同的也可能是不同的
- 通过反射可以在让变量在interface{}和reflect.Value之间相互转换
- 使用反射的方式来取得变量的值(并返回对应的类型),要求是据类型匹配,而不能使用其他
- 通过反射的来修改变量,注意当使用SetXxx方法来设置需要对应指针类型来完成,这样才改变传入变量的值,同时需要使用到reflect.Value.Elem()方法。rVal.Elem().SetInt()
- reflect.Value.Elem()等价于从指针中取出数据
package main |
//案例:使用反射来遍历结构体字段,调用结构体方并获取结构体标签的值 |
网络编程—TCP Socket编程
Golang的主要设计目标之一就是面向大规模后端服务程序,网络通信这块是服务器程序必不可少也是至关重要的一部分
网络编程的基础知识:计算机间要相互通讯,必须要求网线、网卡或无线网卡
网络编程的两种形式:
- TCP Socket编程:是网络编程的主流。之所以叫TCP Socket编程是因为底层基于TCP/IP协议的
- b/s结构的http编程:我们使用浏览器去访问服务器时,使用的就是http协议,而http协议底层依旧是用TCP Socket实现的
协议(TCP/IP):TCP/IP(Transmission Control Protocol/Internet Protocol)的简写,中文译名为传输控制协议/因特网互联协议,又叫网络通讯协议。这个协议是Internet最基本的协议、Internet国际互联网的基础,简单的说就是有网络层的IP协议和传输层的TCP协议组成的
网络编程的基础知识
IP地址
概述:每个internet上的主机和路由器都有一个ip地址,他包括网络号和主机号,ip地址有Ipv4(32位)或者Ipv6(128位),可以通过ipconfig查看
端口
我们这里所指的端口不是物理意义上的端口,而是特指TCP/IP协议中的端口,是逻辑意义上的端口
端口的分类:
0为保留端口
1~1024是固定端口
又叫有名端口,即被某些程序固定使用,一般程序员不使用。
7:echo服务
21:ftp使用
22:ssh远程登录协议
23:Telnet使用
25:smtp使用
80:iis使用
1025~65535是动态端口,程序员可用
使用细节和注意事项
- 在计算机(尤其是做服务器)要尽可能的少开端口
- 一个端口只能被一个程序监听
- 如果使用netstart -an可以查看本机有哪些端口在监听
- 可以使用netstart -anb来查看监听端口的pid,在结合任务管理器关闭不安全的端口
TCP Socket编程的客户端和服务器端
下图为Golang Socket编程中客户端和服务器的网络分布
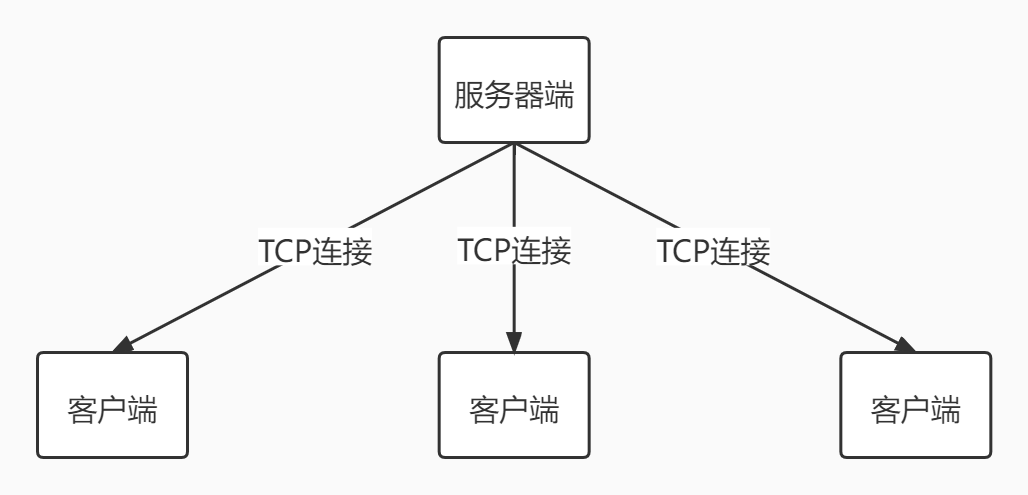
服务器端的处理流程
- 监听端口
- 接收客户端的TCP链接,建立客户端与服务器端的链接
- 创建Goroutine,处理该链接的请求(通常客户端会通过链接发送请求包)
package main |
注意事项和使用细节:
在conn.Read()函数使用时,所返回的n值可以限制读取的数据长度,防止切片申请过长时输出大量空格
客户端的处理流程
- 建立与服务器的链接
- 发送数据请求,接收服务器端返回的结果数据
- 关闭链接
package main |
Redis
Redis的基本介绍和操作原理
基本介绍:
- Redis是NoSQL数据库,不是传统的关系型数据库。官网:https://redis.io/和http://www.redis.cn/
- Redis:Remote Dictionary Server(远程字典服务器),Redis性能非常高,单机能够达到15w qps,通常适合做缓存,也可以持久化
- 是完全开源免费的,高性能的(key/value)分布式内存数据库,基于内存运行并支持持久化的NoSQL数据口,是最热门的NoSQL数据库之一,也称为数据结构服务器
下载后直接解压就有Redis的服务器端程序(redis-server.exe)和客户端程序(redis-cli.exe),直接双击即可运行,并不需要安装
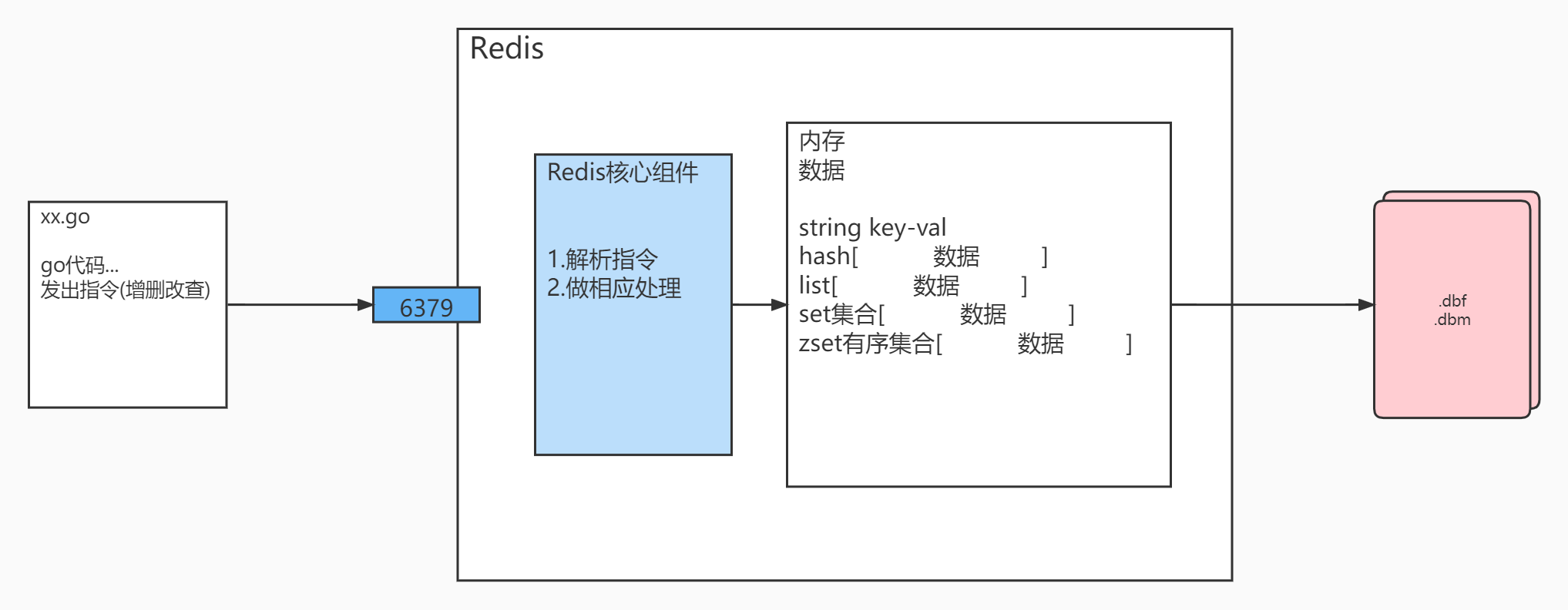
除了通过.go程序发出指令外,还可以通过Redis自带的redis-cli.exe客户端发出指令
说明:Redis安装好后,默认有16个数据库,初始默认使用0号库,编号为0…15
- 添加key-val [set]
- 查看当前redis的所有key [keys *]
- 获取key对应的值 [get key]
- 切换redis数据库 [select index]
- 如何查看当前数据库的key-val数量 [dbsize]
- 清空当前数据库的key-val和清空所有数据库的key-val [flushdb]、[flushall]
Redis数据类型和crud操作
Redis的五大数据类型:String(字符串)、Hash(哈希)、List(列表)、Set(集合)、zset(sorted set:有序集合)
String(字符串)-介绍
string是redis最基本的类型,一个key对应一个value
string类型是二进制安全的。除了普通的字符串外,也可存放图片等数据
redis中字符串value最大是512M
set指令:如果存在相当于修改,如果不存在相当于添加
其他指令:set、get、del
String-注意事项和细节说明:
- setex(set with expire)键秒值
- mset[同时设置多个key-value]
- mget[同时获取多个key-value]
Hash(哈希)-介绍
Redis hash 是一个键值对集合
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象
hset指令:hset key feild value
其他指令:hset、hget、hdel
Hash-注意事项和细节说明:
- 再给数据设置字段时可以一步一步设置,也可以使用hmset和hmget一次性设置多个field的值和返回多个field的值
- hlen统计一个hash有几个元素
- hexists key field查看哈希表key中field是否存在
List(列表)-介绍
列表是简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表头部(左边)或者尾部(右边)
List本质是个链表,List的元素时有序的,元素的值可以重复
lpush指令:lpush key value1 value2…头插法插入
lrange指令:lrange key 0 -1全部取出,从头取出
返回值列表key中指定区间内的元素,区间以偏移量start和stop指定。下标(index)参数start和stop都以0为底,以0表示列表的第一个元素,以1表示列表的第二个元素,**-1表示列表的最后一个元素**,-2表示列表的倒数第二个元素
其他指令:lpush(从左边插入)、rpush(从右边插入)、lrange(从左边取出)、lrange(从右边取出)
List-注意事项和细节说明:
lindex按照索引下标获得元素(从左到右,标号从0开始)
LLEN key
返回值列表key的长度,如果key不存在,则key被解释为一个空列表返回0
List的其他说明
List数据,可以从左或从右插入
如果值全部移除,对应的键也就消失了
Set(集合)-介绍
Redis的Set是string类型的无需集合
底层是Hash Table数据结构,Set也可存放很多字符串元素,字符串元素是无序的,且元素的值不能重复
sadd指令:sadd key value
其他指令:sadd、smembers(取出所有值)、sismember(判断值是否是成员)、srem(删除指定值)
Go操作Redis
安装第三方开源Redis库
- 使用第三方开源Redis库Redis开源库
- 在使用Redis前,先安装第三方Redis库,在GOPATH路径下执行安装指令
特别说明:在安装Redis库前,去报已经安装并配置了Git,因为从Github下载Redis库需要使用Git
package main |
对哈希进行操作时,返回值使用redis.Strings接收则最终为string类型切片
通过查看redis文档获取操作
//通过Go向redis写入数据 |
给数据设置有效时间
_, err := c.Do("expire", "name", 10) |
对String、Hash、List、Set操作信息见第二节及Redisdoc
Redis连接池
说明:通过Golang对Redis操作,还可以通过连接池
- 实现初始化一定数量的连接,放入连接池
- 当Go需要操作Redis是,直接从Redis连接池取出连接即可
- 这样可以节省临时获取Redis连接的时间,从而提高效率
var pool *redis.Pool |
如果需要从连接池中取出连接,则需要连接池不可关闭


