html页面结构介绍 <!DOCTYPE html > <html lang ="en" > <head > <meta charset ="UTF-8" > <title > Title</title > </head > <body > <table width ="200px" height ="200px" border ="1px" > <tr > <td > </td > </tr > </table > <ul > <li > </li > </ul > <ol > <li > </li > </ol > <a href ="http://www.xxx.com/" > </a > </body > </html >
爬虫 如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据
通过一个程序,根据url进行爬取网页,获取有用信息
使用程序模拟浏览器,去向服务器发送请求,获取响应信息
爬虫核心 爬取网页:爬取整个网页,包含网页的所有内容
解析数据:将网页中你所得到的数据进行解析
难点:爬虫和反爬虫之间的博弈
爬虫用途 数据分析/人工数据集
社交软件冷启动
舆情监控
竞争对手监控
爬虫分类 通用爬虫:
实例:百度、360、google等搜索引擎
功能:访问页面、抓取数据、数据存储、数据处理、提供检索服务
robots协议:
一个约定俗成的协议,添加robots.txt文件,来说明本网站哪些内容不可以被抓取,起不到限制作用
自己写的爬虫无需遵守
网络排名:
根据pagerank算法进行排名(参考各网站流量、点击率等指标)
百度竞价排名
确定:
抓取的数据多数无用
不能根据用户需求来精准获取数据
聚焦爬虫:
功能:根据需求实现爬虫,抓取需要的数据
设计思路:
确定要爬取的url
模拟浏览器通过http协议访问url,获取服务器返回的html代码
解析html字符串(根据一定规则提取需要的数据)
反爬手段
urllib 基本使用 import urllib.requesturl = 'http://www.baidu.com' response = urllib.request.urlopen(url) content = response.read().decode('utf-8' ) print (content)
常用类型和方法 response = urllib.request.urlopen(url) print (type (response))
content1 = response.read(5 ) content2 = response.readline() content3 = response.readlines() code = response.getcode() url = response.geturl() headers = response.getheaders()
下载到本地 urllib.request.urlretrieve(url=url, filename='baidu.html' ) url_img = '图片地址' urllib.request.urlretrieve(url=url_img, filename='xx.jpg' ) url_video = '视频地址' urllib.request.urlretrieve(url=url_video, filename='xx.mp4' )
请求对象定制 url组成https://www.baidu.com/s?wd=xxx
协议:http/https
主机:www.baidu.com
端口号:http80、https443、mysql3306、redis6379、oracle1521、mongodb27017等
路径:s
参数:wd=xxx
锚点:#
import urllib.requesturl = 'https://www.baidu.com' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' } request = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(request) content = response.read().decode('utf-8' ) print (content)
编解码 GRT请求方式:urllib.parse.quote() import urllib.request, urllib.parseurl = 'https://www.baidu.com/s?wd=' name = urllib.parse.quote('周杰伦' ) url = url + name headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' } request = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(request) content = response.read().decode('utf-8' ) print (content)
GET请求方式:urllib.parse.urlencode() 在实际开发过程中遇到较长url,使用quote非常麻烦
import urllib.request, urllib.parseurl = 'https://www.baidu.com/s?' data = { 'wd' : '周杰伦' , 'sex' : '男' , 'location' : '中国台湾省' } new_data = urllib.parse.urlencode(data) url = url + new_data headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' } request = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(request) content = response.read().decode('utf-8' ) print (content)
POST请求方式 post请求方式的参数必须进行编码,data = urllib.parse.urlencode(data)
编码之后必须调用encode方法,data = urllib.parse.urlencode(data).encode('utf-8')
参数是放在请求对象定制的方法中,request = urllib.request.Request(url=url, data=data, headers=headers)
import urllib.request, urllib.parseurl = 'https://fanyi.baidu.com/sug' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' } data = { 'kw' : 'spider' } data = urllib.parse.urlencode(data).encode('utf-8' ) request = urllib.request.Request(url=url, data=data, headers=headers) response = urllib.request.urlopen(request) content = response.read().decode('utf-8' ) print (content)
ajax GET请求 import urllib.requestimport urllib.parseurl = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' } request = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(request) content = response.read().decode('utf-8' ) with open ('douban.json' , 'w' , encoding='utf-8' ) as fp: fp.write(content)
import urllib.requestimport urllib.parsedef create_request (page ): base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&' data = { 'start' : (page - 1 ) * 20 , 'limit' : 20 } data = urllib.parse.urlencode(data) url = base_url + data headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' } request = urllib.request.Request(url=url, headers=headers) return request def get_content (request ): response = urllib.request.urlopen(request) content = response.read().decode('utf-8' ) return content def download (content, page ): with open ('douban' + str (page) + '.json' , 'w' , encoding='utf-8' ) as fp: fp.write(content) if __name__ == '__main__' : start_page = int (input ('请输入起始的页码:' )) end_page = int (input ('请输入结束的页码:' )) for page in range (start_page, end_page + 1 ): request = create_request(page) content = get_content(request) download(content, page)
POST请求 在headers中出现X-Requested-With:XMLHttpRequest说明该请求为ajax请求
import urllib.requestimport urllib.parsedef create_request (page ): url = 'https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname' data = { 'cname' : '北京' , 'pid' : '' , 'pageIndex' : page, 'pageSize' : 10 } data = urllib.parse.urlencode(data).encode('utf-8' ) headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' } request = urllib.request.Request(url=url, data=data, headers=headers) return request def get_content (request ): response = urllib.request.urlopen(request) content = response.read().decode('utf-8' ) return content def download (content, page ): with open ('kfc' + str (page) + '.json' , 'w' , encoding='utf-8' ) as fp: fp.write(content) if __name__ == '__main__' : start_page = int (input ('请输入起始的页码:' )) end_page = int (input ('请输入结束的页码:' )) for page in range (start_page, end_page + 1 ): request = create_request(page) content = get_content(request) download(content, page)
异常 URLError类是HttpError类的子类
导入的包urllib.error中的urllib.error.HttpError,urllib.error.URLError
http错误:http错误时针对浏览器无法连接到服务器而增加出来的错误提示。引导并告诉浏览器该页是哪里出了问题
通过urllib发送请求的时候,有可能会发送失败,这个时候如果想让代码更加健壮,可以通过try-except进行捕获异常,异常有两类URLError、HttpError
cookie登录 适用的场景:在数据采集时候,需要绕过登录,进入到某个页面
import urllib.requestimport urllib.parseurl = 'https://weibo.cn/.../info' headers = { ... } request = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(request) content = response.read().decode('utf-8' ) with open ('weibo.html' , 'w' , encoding='utf-8' ) as fp: fp.write(content)
Handler处理器 为什么需要handler处理器
urllib.request.Request(url=url, data=data, headers=headers)可以定制请求头
urllib.request.urlopen(url)不能定制请求头
Handler定制更高级的请求头(随着业务逻辑的复杂,请求对象的定制已经满足不了我们的需求(动态cookie和代理不能使用请求对象的定制))
基本使用 import urllib.requesturl = 'http://www.baidu.com' headers = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' } request = urllib.request.Request(url=url, headers=headers) handler = urllib.request.HTTPHandler() opener = urllib.request.build_opener(handler) response = opener.open (request) content = response.read().decode('utf-8' ) print (content)
代理服务器 代理的常用功能:
突破自身的IP访问限制,访问国外站点
访问一些单位或团体内部资源
提高访问速度(通常代理服务器设置一个较大的硬盘缓冲区,当有外界信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同信息时,则直接由缓冲区中取出信息传给用户)
隐藏真实IP(上网者也可以通过这种方式隐藏自己的IP,免收攻击)
代码配置代理:
创建Request对象
创建ProxyHandler对象
用handler对象创建opener对象
使用opener.open函数发送请求
import urllib.requesturl = 'http://www.baidu.com/s?wd=ip' headers = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' } request = urllib.request.Request(url=url, headers=headers) poxies = { 'http' : '代理ip地址:端口号' } handler = urllib.request.ProxyHandler(proxies=poxies) opener = urllib.request.build_opener(handler) response = opener.open (request) content = response.read().decode('utf-8' ) with open ('daili.html' , 'w' ) as fp: fp.write(content)
代理池 在爬取过程中,如果ip被封则会出现很大困扰,一般我们使用代理池来解决
import urllib.requestimport randomurl = 'http://www.baidu.com/s?wd=ip' headers = { 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' } request = urllib.request.Request(url=url, headers=headers) proxies_pool = [ {'http' : '代理ip地址:端口号' }, {'http' : '代理ip地址:端口号' } ] proxies = random.choice(proxies_pool) handler = urllib.request.ProxyHandler(proxies=proxies) opener = urllib.request.build_opener(handler) response = opener.open (request) content = response.read().decode('utf-8' ) with open ('daili.html' , 'w' ) as fp: fp.write(content)
cookie库 解析 xpath xpath使用:需要安装xpath-helper插件(chrome浏览器扩展程序)重启浏览器后ctrl+shift+x出现小黑框
安装lxml库:pip install lxml
导入lxml.etree:from lxml import etree
解析本地文件:html_tree = etree.parse('xx.html')
解析服务器响应文件:html_tree = etree.HTML(response.read().decode('utf-8'))
html_tree.xpath(xpath路径)
xpath基本语法:
路径查询:
//:查询所有子孙节点,不考虑层级关系
/:找直接子节点
谓词查询:
//div[@id]//div[@id="maincontent"]
属性查询://@class
模糊查询:
包含xx的://div[contains(@id,'xx')]
以xx开头的://div[starts-with(@id,'xx')]
内容查询://div/h1/text()
逻辑运算:极少用到
并且(and)://div[@id='head' and @class='s_down']
或(|)//title | //price
import urllib.requestfrom lxml import etreeurl = 'http://www.baidu.com' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' } request = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(request) content = response.read().decode('utf-8' ) tree = etree.HTML(content) result = tree.xpath('//input[@id="su"]/@value' ) print (result)
import urllib.requestfrom lxml import etreedef creat_request (page ): if page == 1 : url = '' else : url = '' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36' } request = urllib.request.Request(url=url, headers=headers) return request def get_content (request ): response = urllib.request.urlopen(request) content = response.read().decode('utf-8' ) return content def down_img (content ): tree = etree.HTML(content) src_list = tree.xpath('' ) name_list = tree.xpath('' ) for i in range (len (name_list)): name = name_list[i] src = src_list[i] url = 'https:' + src urllib.request.urlretrieve(url=url, filename='./img/' + name + '.jpg' ) if __name__ == '__main__' : start_page = int (input ('请输入起始页码:' )) end_page = int (input ('请输入结束页码:' )) for page in range (start_page, end_page + 1 ): request = creat_request(page) content = get_content(request) down_img(content)
jsonpath jsonpath使用:
pip安装:pip install jsonpath
jsonpath使用:
obj = json.load(open('json文件', 'r', encoding='utf-8'))ret = jsonpath.jsonpath(obj, 'jsonpath语法')
jsonpath只能解析本地文件
XPath
JSONPath
Description
/
$
表示根元素
.
@
当前元素
/
. or []
子元素
..
n/a
父元素
//
..
递归下降
*
*
通配符,表示所有元素
@
n/a
属性访问字符
[]
[]
子元素操作符
|
[,]
连接操作符,在XPath结果合并其他节点集合,JSONPath允许name或者数组索引
n/a
[start: end:step]
数组分割操作
[]
?()
应用过滤表达式
n/a
()
脚本表达式,使用在脚本引擎下面
()
n/a
XPath分组
import urllib.requestimport jsonimport jsonpathurl = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1675923454318_404&jsoncallback=jsonp405&action=cityAction&n_s=new&event_submit_doGetAllRegion=truehttps://dianying.taobao.com/cityAction.json?activityId&_ksTS=1675923454318_404&jsoncallback=jsonp405&action=cityAction&n_s=new&event_submit_doGetAllRegion=true' headers = { } request = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(request) content = response.read().decode('utf-8' ) content = content.split('(' )[1 ].split(')' )[0 ] with open ('city.json' , 'w' , encoding='utf-8' ) as fp: fp.write(content) obj = json.load(open ('city.json' ,'r' , encoding='utf-8' )) city_list = jsonpath.jsonpath(obj, '$..regionName' ) print (city_list)
BeautifulSoup 简称为bs4,与lxml一样,是一个html的解析器,主要功能也是解析和提取数据
优点:接口设计人性化,使用方便
缺点:效率没有lxml的效率高
bs4的使用:
基本语法:
节点信息:
获取节点内容:适用于标签中嵌套标签的结构obj.get_text()
节点的属性
获取节点属性:
from urllib import requestfrom bs4 import BeautifulSoupurl = 'https://www.starbucks.com.cn/menu/' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36' } req = request.Request(url=url, headers=headers) response = request.urlopen(req) content = response.read().decode('utf-8' ) soup = BeautifulSoup(content, 'lxml' ) name_list = soup.select('ul[class="grid padded-3 product"] strong' ) for name in name_list: print (name.get_text())
Selenium
Selenium是一个用于Web应用程序测试的工具
Selenium测试直接运行在浏览器中,就想真正的用户在操作一样
直接通过各种driver(FirfoxDriver、InternetExplorerDriver、OperaDriver、ChromeDriver)驱动真是浏览器完成测试
Selenium也是支持无界面浏览器操作的
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
基本使用 from selenium import webdriverfrom selenium.webdriver.chrome.service import Serviceservice = Service(r'D:\Code\Python\pythonSpiderTest\chromedriver.exe' ) driver = webdriver.Chrome(service=service) url = 'https://www.jd.com/' driver.get(url) content = driver.page_source print (content)
元素定位 自动化要做的就是模拟鼠标和键盘类操作这些元素,点击、输入等等。操作这些元素前首先要找到它们,WebDriver提供很多定位元素的方法
利用ID查找:find_element(By.ID, "value")
利用类名查找:find_element(By.CLASS_NAME, "value")
利用name属性查找:find_elements(By.NAME, "value")
利用xpath查找:find_element(By.XPATH, "value")
利用标签名查找:find_elements(By.TAG_NAME, "value")
利用CSS选择器查找:find_elements(By.CSS_SELETOR, "value")
元素信息
获取元素属性:get_attribute('class')
获取元素文本:text
获取id:id
获取标签名:tag_name
交互
from selenium import webdriverfrom selenium.webdriver.chrome.service import Servicefrom selenium.webdriver.common.by import Byimport timeservice = Service(executable_path='D:\Code\Python\pythonSpiderTest\chromedriver.exe' ) driver = webdriver.Chrome(service=service) url = 'https://www.baidu.com/' driver.get(url) time.sleep(2 ) input = driver.find_element(By.ID, 'kw' )input .send_keys('周杰伦' )time.sleep(2 ) button = driver.find_element(By.ID, 'su' ) button.click() time.sleep(2 ) js = 'document.documentElement.scrollTop = 100000' driver.execute_script(js) time.sleep(2 ) button = driver.find_element(By.XPATH, '//a[@class="n"]' ) button.click() time.sleep(2 ) driver.back() time.sleep(2 ) driver.forward() time.sleep(2 ) driver.quit()
Phantomjs 目前不常使用
一个无界面的浏览器
支持页面元素查找,js的执行等
由于不进行css和gui渲染,运行效率要比真实的浏览器快很多
使用Phantomjs:
获取PhantomJS.exe文件路径path
driver = webdriver.PhantomJS(path)driver = get(url)保存屏幕快照:driver.save_screenshot('xx.png')
Chrome handless Chrome-handless模式,Google针对Chrome浏览器59版新增的一种模式,可以在不打开UI界面的情况下使用Chrome
系统要求:
from selenium import webdriverfrom selenium.webdriver.chrome.options import Optionschrome_options = Options() chrome_options.add_argument("--headless" ) chrome_options.add_argument("disable-gpu" ) path = r'C:\Program Files\Google\Chrome\Application\chrome.exe' chrome_options.binary_location = path driver = webdriver.Chrome(chrome_options=chrome_options)
from selenium import webdriverfrom selenium.webdriver.chrome.options import Optionsdef share_driver (): chrome_options = Options() chrome_options.add_argument("--headless" ) chrome_options.add_argument("disable-gpu" ) path = r'C:\Program Files\Google\Chrome\Application\chrome.exe' chrome_options.binary_location = path driver = webdriver.Chrome(chrome_options=chrome_options) return driver driver = share_driver() url = 'xx.com' driver.get(url)
Requests Request是唯一一个非转基因的Python HTTP库
基本使用 官方文档:http://cn.python_request.org/zh_CN/latest/
快速上手:http://cn.python_request.org/zh_CN/latest/user/quickstart.html
安装:pip install requests
response的属性以及类型:response = requests.get(url=url)
类型:models.Request
response.text:获取网站源码
response.encoding:访问或定制编码方式
response.url:获取请求的url
response.content:响应的字节类型
response.status_code:响应的状态码
response.headers:响应的头信息
GET请求 import requestsurl = 'http://www.baidu.com/s?' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36' } data = { 'wd' : '北京' } response = requests.get(url=url, params=data, headers=headers) content = response.text print (content)
参数使用params传递
参数无需urlencode编码
不需要进行请求对象定制
请求资源中的’?’可以加也可以不加
POST请求 import requestsimport jsonurl = 'https://fanyi.baidu.com/sug' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36' } data = { 'kw' : 'eye' } response = requests.post(url, headers=headers, data=data) content = response.text obj = json.loads(content, encoding='utf-8' ) print (obj)
post请求不需要编解码
post请求的参数是data
不需要进行请求对象定制
代理 import requestsurl = 'https://fanyi.baidu.com/s' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36' } data = { 'wd' : 'ip' } proxy = { 'http' : 'xxx' } response = requests.post(url, headers=headers, data=data, proxies=proxy) content = response.text with open ('daili.html' , 'w' , encoding='utf-8' ) as fp: fp.write(content)
cookie登录 import requestsfrom lxml import etreeurl = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx' headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36' } response = requests.post(url, headers=headers) content = response.text html_tree = etree.HTML(content) __VIEWSTATE = html_tree.xpath('//input[@name="__VIEWSTATE"]/@value' ) __VIEWSTATEGENERATOR = html_tree.xpath('//input[@name="__VIEWSTATEGENERATOR"]/@value' ) imgCode = html_tree.xpath('//img[@id="imgCode"]/@src' )[0 ] code_url = 'https://so.gushiwen.cn/' + imgCode session = requests.session() response_code = session.get(code_url) content_code = response_code.content with open ('code.jpg' , 'wb' ) as fp: fp.write(content_code) code_name = input ('验证码:' ) url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx' data_post = { '__VIEWSTATE' : __VIEWSTATE[0 ], '__VIEWSTATEGENERATOR' : __VIEWSTATEGENERATOR[0 ], 'from' : 'http://so.gushiwen.cn/user/collect.aspx' , 'email' : 'root@qq.com' , 'pwd' : 'root' , 'code' : code_name, 'denglu' : '登录' } response_post = session.post(url=url_post, headers=headers, data=data_post) content_post = response_post.text with open ('geshiwen.html' , 'w' , encoding='utf-8' ) as fp: fp.write(content_post)
通过模拟cookie登录古诗文网站,需要注意隐藏域和验证码问题
Scrapy scrapy是一个为了爬取网站数据,提供结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序过程
安装scrapy:pip install scrapy
项目组成
spiders
_init.py _
自定义爬虫文件.py(由我们自己创建,是实现爬虫核心功能的文件)
_init _.py
item.py(定义数据结构的地方,是一个继承自scrapy.Item的类)
middlewares.py(中间件,代理)
pipeline.py(管道模式,里面只有一个类,用于处理下载数据的后需处理,默认是300优先级,值越小优先级越高(1-1000))
settings.py(配置文件)
scrapy项目的创建和运行
创建爬虫项目:scrapy startproject 项目名
项目名不允许使用数字开头,也不允许出现中文
创建爬虫文件:
在spiders文件夹中创建爬虫文件:cd 项目名\项目名\spiders
创建爬虫文件:scrapy genspider 爬虫名字 爬取网页
运行爬虫代码:scrapy crawl 爬虫名字
获取响应字符串:response.text
获取二进制数据:response.body
直接使用xpath方法解析response内容:response.xpath
提取seletor对象的data属性值:response.extract()
提取seletor列表的第一个数据:response.extract_first()
scrapy架构组成
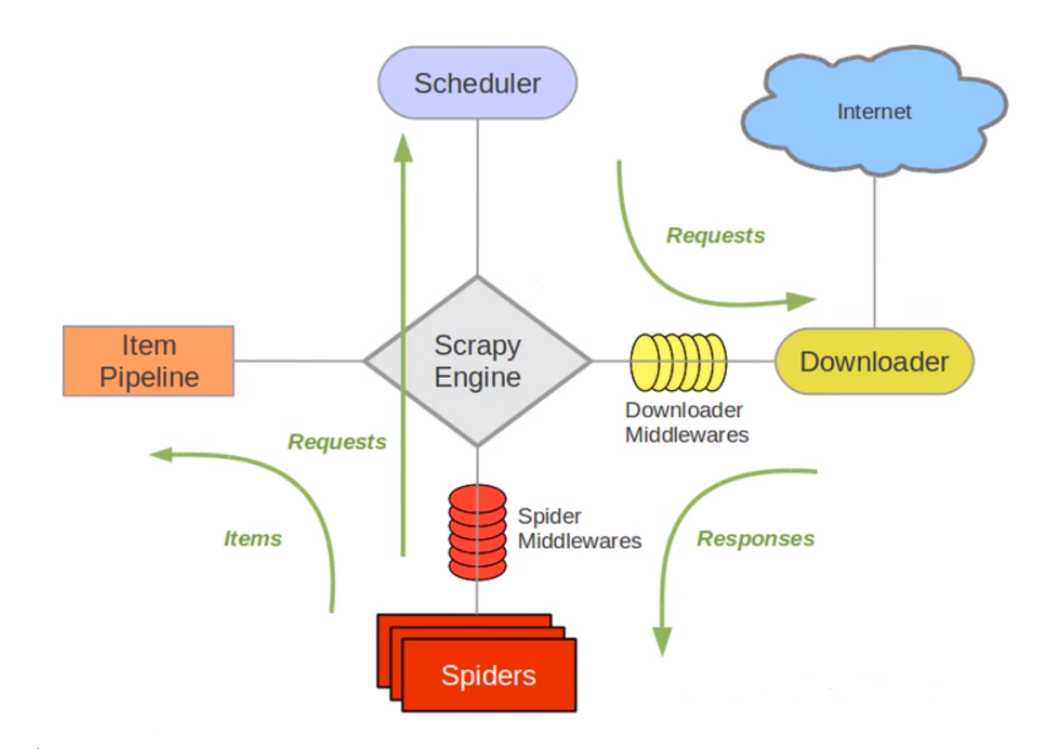
引擎:自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
下载器:从引擎处获取到请求对象后,请求数据
spiders:Spiders类定义了如何爬取某个(或某些)网站。包括了爬取动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取Items)
调度器:有自己的调度规则,无需关注
管道(Item pipelines):最终处理数据的管道,会预留接口供我们处理数据(Item用于定义数据结构,piplines用于下载数据)
当Item在spider中被收集之后,它将会被传递到Item pipeline,一些组件会按照一定的顺序执行对Item的处理每个item pipeline组件(有时称之为”Item pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理
Item pipline的一些应用:
清理HTML数据
验证爬虫的数据(检查Item包含某些字段)
查重(并丢弃)
将爬取结果保存到数据库中
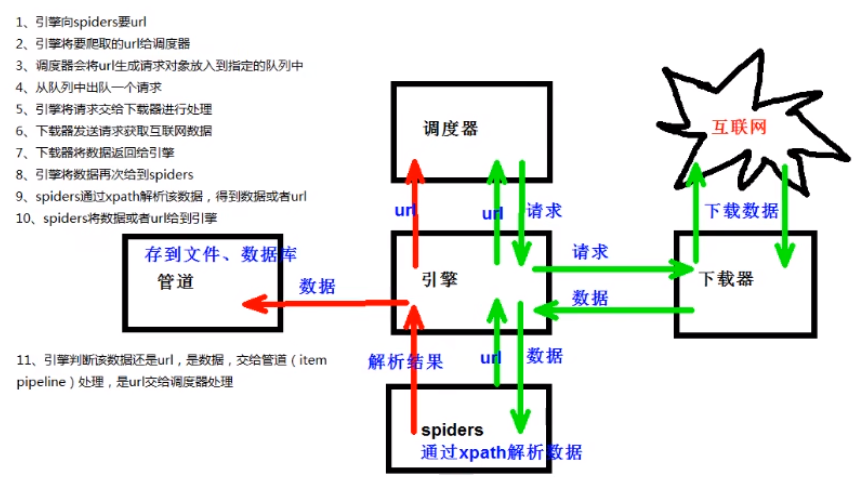
scrapy工作原理
### scrapy shell
Scrapy shell是Scrapy终端,是一个交互终端,供您在未启动spider的情况下尝试及调节您的代码。其本意是用来测试提取数据的代码,不过可以将其作为正常的python终端没在上面测试任何的python代码
该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取网页中提取的数据,在编写spider时,该终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦
安装ipython:pip install ipython
如果您安装了IPython,Scrapy终端将使用IPython(代替标准的Python终端)。IPython终端与其他相比更为强大,提供智能的自动补全、高亮输出等特性
使用:
scrapy shell www.xxx.comscrapy shell http://www.xxx.comscrapy shell 'http://www.xxx.com'scrapy shell 'www.xxx.com'
yield 带有yield的函数不再是一个普通函数,而是一个生成器generator,可用于迭代
yield是一个类似return的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行
简要理解:yield就是return返回一个值,并记住这个返回的位置,下次迭代就从这个位置后(下一行)开始
import scrapyfrom dangdang.items import DangdangItemclass DangSpider (scrapy.Spider): name = "dang" allowed_domains = ["category.dangdang.com" ] start_urls = ["http://category.dangdang.com/cp01.01.02.00.00.00.html" ] base_url = "http://category.dangdang.com/pg" page = 1 def parse (self, response ): li_list = response.xpath("//ul[@id='component_59']/li" ) for li in li_list: src = li.xpath(".//img/@data-original" ).extract_first() if src: src = src else : src = li.xpath(".//img/@src" ).extract_first() name = li.xpath(".//img/@alt" ).extract_first() price = li.xpath(".//p[@class='price']/span[1]/text()" ).extract_first() book = DangdangItem(src=src, name=name, price=price) yield book if self.page < 100 : self.page += 1 url = self.base_url + str (self.page) + '-cp01.01.02.00.00.00.html' yield scrapy.Request(url=url, callback=self.parse)
from itemadapter import ItemAdapterimport urllib.requestclass DangdangPipeline : def open_spider (self, spider ): self.file = open ('dangdang.json' , 'w' , encoding='utf-8' ) def process_item (self, item, spider ): self.file.write(str (item) + '\n' ) return item def close_spider (self, spider ): self.file.close() class DangdangPipeline2 : def process_item (self, item, spider ): url = 'http:' + item.get('src' ) filename = './books/' + item.get('name' ) + '.jpg' urllib.request.urlretrieve(url=url, filename=filename) return item
import scrapyclass DangdangItem (scrapy.Item): src = scrapy.Field() name = scrapy.Field() price = scrapy.Field()
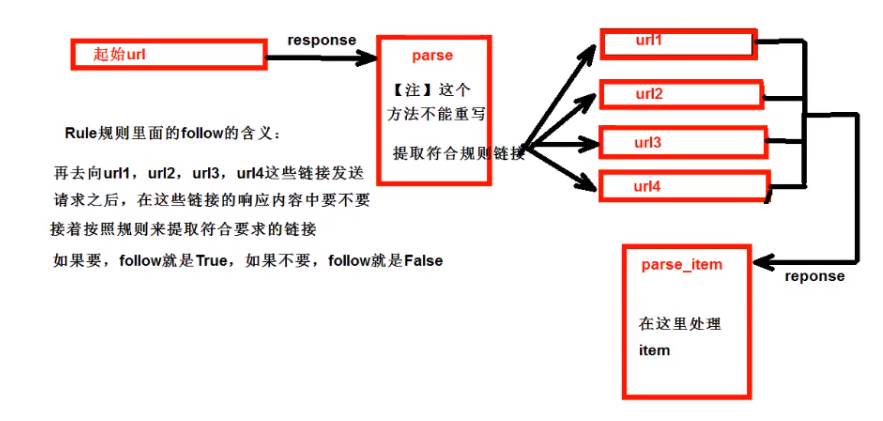
CrawlSpider 继承自scrapy.Spider
CrawlSpider可以定义规则,在解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求。如果有需要跟进链接需求,爬取网站之后需要提取链接再次进行爬取,可以使用CrawlSpider
提取链接:scrapy.linkextractors.LinkExtractor
正则表达式:allow = ()
XPath:restrict_xpaths = ()
选择器:restrict_css = ()
提取链接:link.extract_links(response)
日志信息与日志等级 日志级别:
CRITICAL:严重错误
ERROR:一般错误
WARNING:警告
INFO:一般信息
DEBUG:调试信息
默认的日志等级为DEBUG,只要出现DEBUG或DEBUG以上等级的日志全部打印
settings.py文件设置:
LOG_FILE:将屏幕显示的信息全部记录在文件中,屏幕不在显示,文件后缀为.log
LOG_LEVEL:设置日志显示等级,就是显示哪些,不显示哪些
POST请求 class TestSpider (scripy.Spider): name = 'test' allow_domains = ['xxx' ] def start_requests (self ): url = 'xxx' data = { 'xx' : 'xx' } yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second) def parse_second (self, response ): content = response.text obj = json.loads(content, encoding='utf-8' )